Artillery 부하 테스트 해보기
1. POST 데이터 구하기 (csv)
post 테스트를 하기 위해서.. 음식 관련한 정보가 필요했다. 부하 테스트에 사용될 놈들이었다.
공공데이터 포털에 들어가.. 음식 이름이 담긴 csv 파일을 다운받아보았다. 파일 이름을 'food-name-db.csv'로 적당히 바꾸고, UTF-8 인코딩을 적용하여 저장한 뒤 확인해보았다.
으음~ 뭔가 많이 있지만 음식 이름으로 사용할 5번째 column(index기준)만 필요할 것 같다. 해당 column만 뽑아서 새로운 csv 파일을 만들어야겠다. 그러기 위해 python의 csv 모듈을 사용해서 5번째 column들만 뽑아 새로운 csv파일을 작성하는 스크립트를 짰다.
import csv
content = []
with open('food-name-db.csv','r') as readcsv:
reader = csv.reader(readcsv)
for row in reader:
content.append([row[4]])
with open('recipe-steps.csv','w',newline='') as writecsv:
writer = csv.writer(writecsv)
for row in content:
writer.writerow(row)csv 파일 row 각각의 4번째 열을 뽑아서 content list에 담은 뒤,, 'recipe-steps.csv'에 작성한 것이 끝이므로 자세한 설명은 생략한다.
특이한 점이 있다면 content.append() 부분에서 행을 2중 리스트로서 담고 있는 부분인데, row[4]는 하나의 string인데 이를 그냥 쌩으로 write해버리면 string 자체를 list of char로 보고 csv 모듈이 지 멋대로 char 단위로 ","를 붙여버리고 만다. 그래서 이 csv파일엔 행을 1개만 써라 라는 명시적인 고지를 했다고 볼 수 있겠다.
아무튼 스크립트를 작성한 김에, 이름과 더불어 레시피의 여러 옵션으로 줄 csv 역시 이것저것 작성해보기 시작했다.
import random, csv
difficulty = ["EASY","NORMAL","HARD"]
cookingTime = ["LESS_THAN_10","LESS_THAN_20", "LESS_THAN_30", "LESS_THAN_60", "LESS_THAN_90","LESS_THAN_120","MORE_THAN_120"]
serving = ["ONE","TWO","THREE","FOUR","MORE"]
with open('recipe-info.csv','w',newline='') as writecsv:
writer = csv.writer(writecsv)
for _ in range(1000):
row = [random.choice(difficulty),
random.choice(cookingTime),
random.choice(serving)]
writer.writerow(row)difficulty, cookingTime, serving 등의 정보를 랜덤으로 뽑아서 (1000,3) 크기를 가진 csv파일을 작성했고..
tags = ["MAIN","SIDE","RICE","SOUP","SALTED","SAUCE","NOODLE","SALAD","FUSION",
"BREAD","DESSERT","DRINK","CANDY","NORMAL","SIMPLE","LUNCHBOX","MIDNIGHT",
"DIET","SNACK","ENTERTAIN","HEALTH","FRY","BOIL","STEAM","ROAST","BIBIM",
"JORIM","RAW"]
with open('recipe-tags.csv','w',newline='') as writecsv:
writer = csv.writer(writecsv)
for _ in range(5000):
row = [random.choice(tags) for _ in range(4)]
writer.writerow(row)레시피에 붙일 태그 enum들을 전부 가져와서 (5000,4) 크기를 가진 csv 파일을 구성하기도 했다. 사실 레시피 태그에 중복이 없는 한 개수에 대한 제한은 없다. 근데 테스트 스크립트에 태그 수까지 조절할 수는 없어서(있는데 내가 귀찮아서 더 안팠을 확률 100%) 그냥 랜덤한 4개를 뽑는 것으로 끝냈다.
csv파일도 여기저기서 더 긁어오고, 스크립트 몇 개 더 작성했지만.. 데이터 수집 및 가공 강좌가 아니므로 이만 생략한다. 그렇게 레시피 생성을 위한 데이터 드래곤볼을 완성했고..
본격적으로 부하 테스트를 위한 스크립트를 짰다.
2. Artillery Script 작성
artillery는 부하 테스트에 사용되는 nodejs기반 라이브러리로써, 스크립트를 작성해서 원하는 내용과 규모로 서버에 http 요청을 날릴 수 있도록 도와준다. 스크립트 구성을 위해 artillery 공식 docs를 좀 팠다. Docs에서 기본적으로 확인할 수 있는 예시 안에서 http 스크립트를 쭉 구성한 모습이다. 파일 확장자는 .yml이다.
config:
target: http://${SERVER_HOST}
defaults:
headers:
Content-Type: "application/json"
phases:
- duration: 60
arrivalRate: 1
rampTo: 5
name: Warm up phase
- duration: 60
arrivalRate: 5
rampTo: 10
name: Ramp up load
- duration: 30
arrivalRate: 10
rampTo: 30
name: Spike phase
payload:
- path: "recipe-title.csv"
fields:
- "title"
- path: "recipe-ingredients.csv"
fields:
- "ingredient1"
- "ingredient2"
- "ingredient3"
- "ingredient4"
- path: "recipe-steps.csv"
fields:
- "step1"
- "step2"
- "step3"
- "step4"
- "step5"
- path: "recipe-info.csv"
fields:
- "difficulty"
- "cookingTime"
- "serving"
- path: "recipe-tags.csv"
fields:
- "tag1"
- "tag2"
- "tag3"
- "tag4"
scenarios:
- name: recipe post test
flow:
- post:
url: "/recipes"
cookie:
JSESSIONID: ${JSESSIONID}
json:
title: "{{ title }}"
cookingTime: "{{ cookingTime }}"
difficulty: "{{ difficulty }}"
serving: "{{ serving }}"
ingredients:
- name: "{{ ingredient1 }}"
amount: "1개"
- name: "{{ ingredient2 }}"
- name: "{{ ingredient3 }}"
- name: "{{ ingredient4 }}"
amount: "4개"
tags:
- tagName: "{{ tag1 }}"
- tagName: "{{ tag2 }}"
- tagName: "{{ tag3 }}"
- tagName: "{{ tag4 }}"
steps:
- stepNumber: 1
description: "{{ step1 }}"
- stepNumber: 2
description: "{{ step2 }}"
- stepNumber: 3
description: "{{ step3 }}"
- stepNumber: 4
description: "{{ step4 }}"
- stepNumber: 5
description: "{{ step5 }}"- config : 테스트 전반적인 설정을 한다.
- target : 요청을 날릴 host를 설정한다.
- defaults.headers : 요청에 기본적으로 탑재될 header를 설정했다. 지금은 JSON 기반 post 요청을 날릴 예정이므로 application/json 값을 넣어주었다.
- phases : 부하테스트의 phase, 즉 단계를 결정한다. 나의 예시에선 Warm up -> Ramp up -> Spike의 총 3페이즈를 구성했다. 1페이즈에선 60초간 초당 1번의 요청에서 시작해 5번까지, 2페이즈에선 60초간 초당 5번의 요청에서 시작해 10번까지, 3페이즈에선 10번에서 30번까지 늘어난다. 각 페이즈의 이름과 실제 날아가는 초당 요청을 보면 무엇을 위한 테스트인지 감이 잡힐 것이다.
- payload : 보통 CS나 소프트웨어 엔지니어링에서 말하는 payload는 데이터의 내용 그 자체이다. payload에선 요청 스크립트에 사용될 데이터 src와 내용을 정의한다.
- path : 데이터를 뽑아올 csv파일 이름 자체를 가리킨다.
- fields : csv 파일의 각 column에 이름을 붙인다. 나의 예시에서, 1번 과정중 태그를 4개로 고정해서 (5000,4) 크기의 csv 파일을 만든 것을 상기하자. 그 각각의 column이 recipe-tags.csv path의 tag1,tag2,tag3,tag4로 명명된 것이다.
- scenarios : 구성을 마치고 실제 스크립트 작성 시작이다. 어떤 요청을 날릴지 설정한다. 보통 여기서 use case에 맞춰 get post 등의 요청을 조절하며 말 그대로 가상 유저가 사이트를 이용하는 "시나리오"를 작성하기도 하는데, 현재는 그냥 레시피 Post에 대한 부하 테스트가 목적이므로 단순하게 구성했다.
- flow.post : 요청 시나리오 플로우를 정의한다. 그 중에서도 POST 요청을 구성했다.
- url : target host의 어떤 path로 요청을 날릴지 정의한다. config의 target과 조합되어 "http://${SERVER_HOST}/recipes" 경로로 요청이 날아갈 것이라고 예상할 수 있다.
- cookie : 현재 프로젝트가 OAuth2의 세션 기반 인증을 사용하고 있고 그에 기반해 레시피-유저간 연관관계를 설정하고 있어서, 유저 로그인 처리가 필요했다.
- json : Request body로 들어갈 json을 구성한다. config.payload에서 읽어온 csv 파일의 각 row들을 이용한다. 이 때 "{{ name }}" 구조로 해당 값을 뽑아내는 문법을 따른다는 것을 짚고 가자. json 바로 밑 단계의 항목들은 json의 key값을 나타내고, "-"로 시작되는 항목들은 json 내부의 array를 나타낸다. 예시에서 보면, title, ingredients, serving이 key이고 그 value로 csv파일의 문자열 값이 그대로 들어갈 것이다. ingredients, tags 등의 경우 해당 key에 대한 value가 array가 된다.
위의 예시에서 구성된 json body는 다음과 같다.
{
"title" : "title",
"difficulty" : "difficulty",
"cookingTime" : "cookingTime",
"serving" : "serving",
"steps" : [
{
"stepNumber" : 1,
"description" : "step1"
}, {
"stepNumber" : 2,
"description" : "step2"
}, {
"stepNumber" : 3,
"description" : "step3"
}, {
"stepNumber" : 4,
"description" : "step4"
}, {
"stepNumber" : 5,
"description" : "step5"
}
],
"ingredients" : [
{
"name" : "ingredient1",
"amount" : "1개"
}, {
"name" : "ingredient2",
}, {
"name" : "ingredient3",
}, {
"name" : "ingredient4",
"amount" : 4개
}
],
"tags" : [
{
"tagName" : "tag1"
}, {
"tagName" : "tag2"
}, {
"tagName" : "tag3"
}, {
"tagName" : "tag4"
}
]
}json body를 구성하는데 yml array를 어떻게 쓰면 되는지, 조금이라도 더 이해가 되었기를...
이제 실제로 부하 테스트를 돌려보자. 커맨드 창에 다음과 같이 입력한다. (실행 커맨드 역시 공식 docs에 나와있다)
$ artillery run --output post-report-rampup.json recipetory-post.yml위 yml파일 이름은 `recipetory-post.yml`이다. yml 파일에 작성한대로 테스트를 시작해달라, 그리고 `post-report-rampup.json`파일에 테스트 결과를 json 포맷으로 담아달라. 하는 커맨드이다. 해당 커맨드를 치고 엔터를 누르면 테스트가 시.작.된.다.
3분이 지난 후, 아래 커맨드를 입력해서 결과를 html파일로 예쁘게 살펴볼 수 있도록 하자.
$ artillery report post-report-rampup.json
3. 결과 확인!
Response time이다. post 요청 후 WAS가 DB에 해당 내용을 저장한 뒤 응답을 내려주기까지 평균 얼마정도 시간이 걸렸냐를 볼 수 있는 metric이다. 중앙값이 해봤자 150ms정도인데 p95가 350ms? 전반적으로 빠르지만 부하가 한 번 걸린 후에 모든 요청 처리가 늦어졌을 것이라고 예상할 수 있는 수치인데,

아니나다를까.. ETIMEOUT error가 "Spike" phase에서 발생했다.
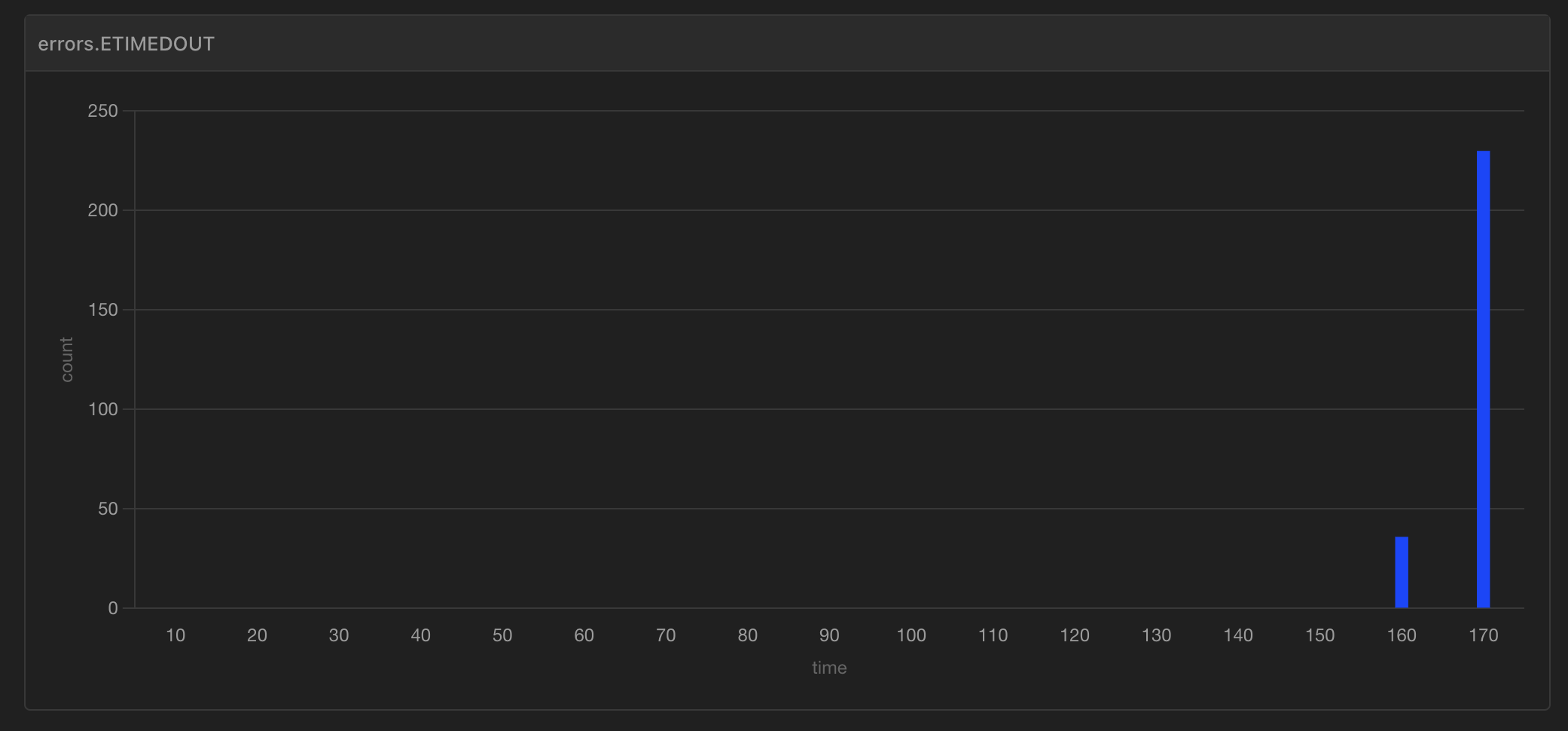

부하 테스트 스크립트에서 보면 알 수 있듯, 우리 테스트는 앞의 60초는 아주 부드럽게(1 -> 5), 그 뒤 60초는 ramp up으로 요청을 점진적으로 늘리다가(5 -> 10), 마지막 30초는 "Spike"로써 1초에 30개까지 post 요청을 늘리는 테스트를 하고 있었다. 10개에서 시작해 진짜 30개 가까이로 post 요청이 늘어나는 160초대(Spike 페이즈)부턴 timeout 에러가 생겨버린 것이다. Spike에 버티지 못하는 유리서버
이렇게 time out 에러가 생겼다면 서버에서 로그를 확인해보지 않지않지않을 수 없다. 뭐가 문제인지 확인해봐야하기 때문이다.. GCP 서버에 ssh 접속해서 도커에 접근하자. 대충 아래 커맨드를 작성해서 최근 나의 스프링부트 어플리케이션의 장애를 살펴보았다.
$ sudo docker logs $CONTAINER_NAME --tail 2000Exception stacktrace로 인한 어.마.무.시.한 길이의 로그가 깔렸는데 눈에 띄게 보이는 키워드를 뽑아보면 아래와 같다.
- Caused by: org.hibernate.exception.JDBCConnectionException: Unable to acquire JDBC Connection [HikariPool-1 - Connection is not available, request timed out after 30000ms.]
- org.springframework.transaction.CannotCreateTransactionException: Could not open JPA EntityManager for transaction
- 2023-08-21T02:55:11.103Z ERROR 1 --- [io-8080-exec-94] o.s.t.s.TransactionSynchronizationUtils : TransactionSynchronization.afterCompletion threw exception
- 2023-08-21T11:14:04.022Z WARN 1 --- [o-8080-exec-713] .m.m.a.ExceptionHandlerExceptionResolver : Failure in @ExceptionHandler com.recipetory.utils.exception.GlobalExceptionHandler#handleGlobalException(Exception)
- org.apache.catalina.connector.ClientAbortException: java.io.IOException: Broken pipe
이런건 통째로 복붙해서 구글링하는게 국룰이다. 결과로 몇가지 , 인사이트를 얻을 수 있었다.
4. 원인?
# Connection is not available ~ after 3000ms.
에러를 대충 보면, 현재 DB와 커넥션을 하려는 어플리케이션 스레드가 30초동안이나 기다리는 상황이 발생했기 때문에 connection time out이 발생한 것으로 보인다.
hibernate에서는 DB와의 연결을 위한 커넥션 풀을 사용하는데(연결 요청마다 스레드를 새로 생성하는 것은 비효율적이기 때문), 기본적으로 그 크기는 10이다. 한 번에 10개까지의 커넥션이 사용 가능하다는 뜻이다. 어플리케이션 스레드가 DB에 연결하기 위해, 스프링 부트에서 JPA에 default로 사용하는 hikari CP(이하 히카리)에 커넥션 요청을 한다. 만약 10개의 커넥션 풀이 전부 사용중이라면, 먼저 커넥션을 사용중인 스레드가 커넥션을 반환할 때까지 대기해야한다. 그리고 지정된 시간, default 설정값으론 30초(=30000ms)가 지나면 Exception을 던진다. 위 상황에서는 30초가 지나도 DB 커넥션을 얻지 못했으므로 JDBCConnectionException을 던진 것이다.
음. 근데 30초 씩이나 걸릴 일인가?
부하테스트 과정 중 서버에 초당 50회의 요청까지 밀려들었다. 부하가 많이 걸리기 전까지 평균적으로 걸렸던 시간은 50~100ms 정도 되었던 듯 한데.. 일단 방금 postman을 통해 확인해본 post 단건 요청에 걸리는 시간은 아래와 같다. 몇 번 더 해보니 평균적으로 50ms가 걸린다고 생각해도 될 것 같다.

한 요청이 커넥션을 점유하면 아주 나이브하게 50ms간 그 스레드를 점유한다고 가정하자. (실제로는 50ms보다도 덜할 것이다) 초당 50개의 요청. 10개의 커넥션 풀. 10개의 각 커넥션이 50ms만에 작업을 완료할 수 있다면 1초당 받을 수 있는 DB 요청 수는 200개 가량이 되어야 한다. 50ms당 10개의 요청을 처리할 수 있으므로, 500ms이면 100개, 1000ms=1s이면 200이기 때문이다. 그런데.. 고작 요청 50개에 스레드가 30초동안이나 기다려야 하는 상황이 말이 되는건가?
.. 싶어서 찾아봤더니 서비스 코드의 이 놈이 문제였다.
@Transactional
public Recipe createRecipe(Recipe recipe,
List<RecipeIngredientDto> ingredients,
String authorEmail) {
// ..
// 5. send notification (@TransactionalEventListener이므로 커밋 후에 실행됨)
eventPublisher.publishEvent(new CreateRecipeEvent(saved));
}위 코드는 아래 메소드를 불러일으킨다.
@TransactionalEventListener
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void handleCreateRecipeEvent(CreateRecipeEvent createRecipeEvent) {
// ..
}@TransactionalEventListener은 PR에서 상황을 볼 수 있듯, 이벤트 리스너 메소드에서 예외가 발생해도 이벤트 리스너를 부른 쪽의 서비스 코드가 영향을 받지 않게 하기 위함이다. 기본적으로 이벤트 리스너를 호출한 쪽의 트랜잭션이 커밋된 이후 실행이 되는데, @Transactional(propagation = Propagation.REQUIRES_NEW) 를 보면 알 수 있듯, 해당 이벤트 리스너 메소드에서 새로운 트랜잭션을 시작한다. 이벤트 리스너에서 새로운 notification entity를 save()하는 로직이 있기 때문이다 ㅜㅇㅜ.
새로운 트랜잭션을 시작한다고? 설마. 싶어서 REQUIRES_NEW가 커넥션을 새로 만드는지 살펴봤다.


커넥션 데드락이 발생한 것이다. recipe create하는 스레드가 커넥션 풀을 하나 잡고있으면서, 이벤트 리스너 처리에 필요한 또다른 커넥션 풀을 하나 더 달라고 호통을 치고 있던 상황이 발생했다.
그렇다면 50ms 이내에 10개 이상의 요청이 동시에 들어오는 부하 상황이라면, 각 커넥션을 점유한 스레드들이 커넥션을 점유한 상태에서 이벤트 리스너를 실행시키기 위한 또다른 커넥션을 요구하고 있을 것이므로 데드락이 발생하게 된다. 그렇기 때문에 커넥션을 30초 동안이나 기다리게 되어버린 것이다.
# ClientAbortException: java.io.IOException: Broken pipe
얘는 artillery의 동작과 관련이 있다. artillery의 부하 테스트에서, artillery는 요청을 날린 뒤 10초 이내에 server response가 돌아오지 않으면 TIMEDOUT fail로 간주하고 요청을 끊는다.
위에서 설명하길 커넥션 요청에 실패하기까지 히카리CP의 기본 설정에 의해 30초가 걸린다. 30초 후 JDBC Exception이 발생하면 어플리케이션 입장에서 exception handler를 동작시키게 되는데, 그걸 받을 유저 커넥션이 끊겨서 broken pipe exception이 발생했다고 이해하면 된다. 결국 위 예외의 연장선이었던 것.
다음은 어떻게 얘네를 타파(?)해볼지 고민해보자.