
1. 인터넷 계층 : 그래서 이 패킷은 어디로 가야하오.
TCP/IP 4계층에서 어플리케이션 계층은 도착한 세그먼트들을 조합하여 사용자가 이용할 수 있도록 하고, 3계층에선 컴퓨터까지 도달한 패킷들을 컴퓨터의 어떤 프로그램이 이용하는지 구분하여 전달한다. 2계층인 인터넷 계층에서는 패킷을 목적지 컴퓨터까지 전달하는 역할을 한다.
인터넷 계층에서 가장 많이 사용하는 프로토콜은 IP 프로토콜이다. 사용 목적에 따라 다른 프로토콜을 사용하는 3,4계층과는 달리 2계층에서 사용하는 프로토콜은 IP 프로토콜입니다~ 라고 말해도 괜찮을 정도다. IP 프로토콜이란, 2계층 PDU인 패킷이 헤더에 적힌 'IP 주소'라고 불리는 컴퓨터의 논리 주소로 향할 수 있도록 하는 프로토콜이다. 이 과정엔 라우터라 불리는 장비가 관여하는데, 인터넷 계층에서 불리는 이 과정을 '라우팅'이라고 한다. IP 주소가 무엇인지, 라우팅 과정은 구체적으로 어떻게 이뤄지는지 살펴보자.
2. IP주소
IP 프로토콜의 가장 중요한 IP 주소는 네트워크 세상에서 컴퓨터의 논리적 주소를 나타내는데 쓰인다. 32비트(약 40억개 표현 가능) 숫자로 나타내지는데, 보통 4개의 8비트(옥텟)으로 나눠 사람이 알아보기 쉬운 10진수로 표현한다.
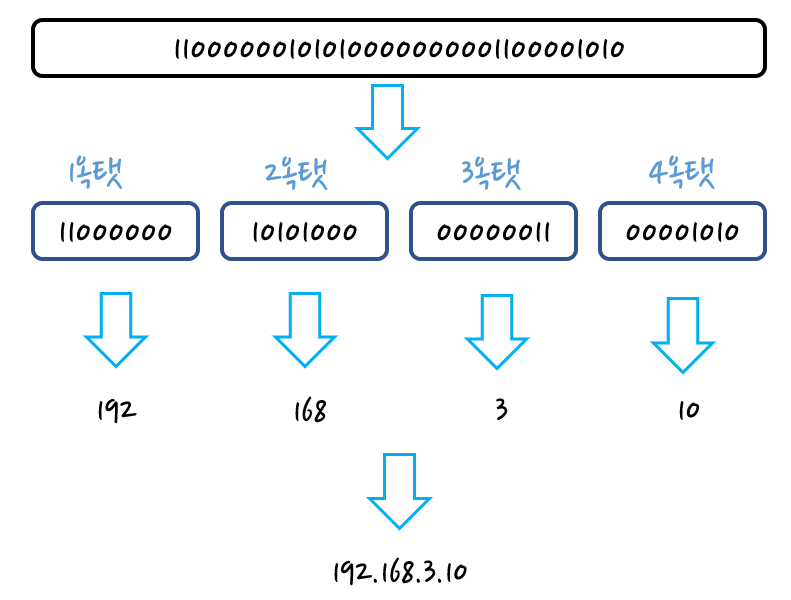
IP주소는 네트워크부 + 호스트부 로 나뉜다. 네트워크부에서 구분하는 것은 말 그대로 목적지가 어느 네트워크에 속하는지인데, 여기서 말하는 네트워크는 일반적으로 같은 사설IP를 쓰는 LAN 범위의 주소를 뜻한다. 사설 IP가 무엇인진 후술하도록 하겠다. 호스트부는 네트워크부로 인해 나눠진 하나의 네트워크 안에서 각각의 호스트(종단점)를 구분하기 위해 사용하는 주소이다.
2-1) 서브넷 마스크 : 네트워크부와 호스트부의 구분
보통 네트워크부는 클래스 A일 경우 8비트, 클래스 B일 경우 16비트, 클래스 C일 경우 24비트의 길이를 가진다. 네트워크부와 호스트부의 경계를 나타내기 위해 서브넷 마스크를 이용한다. 서브넷 마스크란 IP주소와 같은 길이의 비트를 가진 정보로, 네트워크부에 대응하는 비트 자리를 1로, 호스트부에 대응하는 비트 자리를 0으로 설정하여 네트워크부의 길이를 표현하는 수단이다.
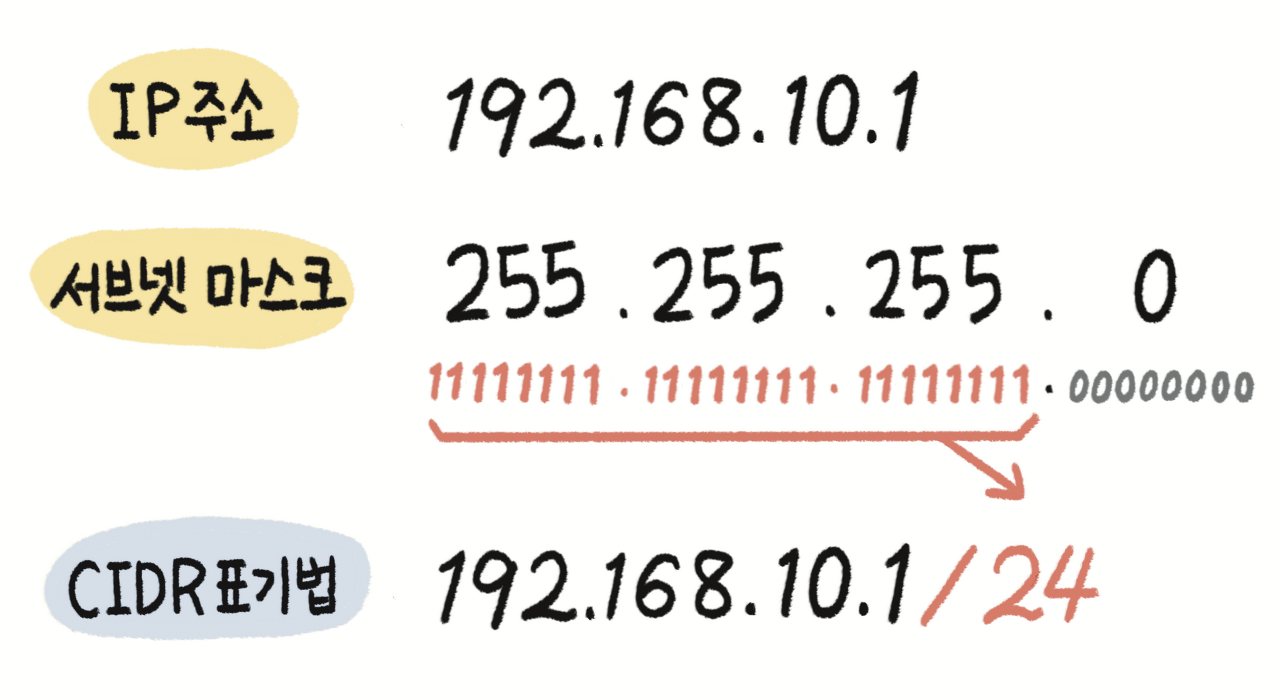
위 그림의 CIDR 표기법처럼 단순하게 네트워크부의 길이를 10진수 숫자로 표기하여 쓸 수도 있다. 추가로, 서브넷 마스크를 이용한 네트워크부/호스트부 경계는 IP 주소를 표현하는 8비트 구분과 일치하지 않을 수도 있다.
2-2) IPv4와 IPv6 : 32bit와 128bit
앞서 소개한 32비트의 IP주소는 버전 4번의 IPv4주소 포맷이다. IPv4로는 32비트=2^32로 약 43억 개의 IP 주소를 표현할 수 있다. 지구의 인구는 70억이 넘고, 한 사람이 사용하는 네트워크 기기의 개수는 날이 갈수록 많아지는 상황에서 약 40억의 숫자는 턱없이 모자라다. 그래서 주소 표현에 32비트가 아닌 128비트를 이용하는 IP주소가 나왔으니, 그것이 IPv6이다. 2^128은 43억과 비교도 안될 정도로 큰 숫자이며, 내 생각으로는 지구가 소멸될 때까지 네트워크 기기를 표현하는덴 부족함이 없을 것이다.
현재 IPv6의 보급이 이뤄지고 있지만, 기존 IPv4의 생명을 연장하는 기술들이 나오고있어 당분간은 두 버전을 함께 이용하고 있다고 한다. 7년 전에 나온 책과 블로그들에 이렇게 적혀 있고 아직도 IPv6 관련한 얘기가 크게 나오지 않는 것을 보면, IPv4의 생명력은 참 끈질긴 것 같다 !
2-3) 공인 IP와 사설 IP
앞서 말한 IPv4의 생명을 연장시켜주는 기술 중 하나이다. 같은 회사 내부, 혹은 같은 공유기를 쓰는 가정 / 범위 내의 기기들에 모두 IP주소를 할당하는 것은 어렵고 비효율적이다. IP 주소 낭비 문제도 있다. 때문에 이러한 네트워크 단위로, 네트워크 내부에서만 유효한 사설IP를 이용할 수 있다. 공인(public) IP 주소로 구분되는 네트워크 내에 사설(private) IP 주소로 구분되는 각 호스트들이 존재하는 것이다.
공인IP주소는 ICANN이라는 공적 단체가 전세계의 국가별로 배정한 IP주소를 바탕으로 동작한다. 세계 단위로 합의된 IP주소를 우리나라의 인터넷 사업자(KT, SKT, LG 등)가 할당받아 자신들의 서비스 가입자들이 이용할 수 있도록 제공한다.
사설IP주소는 앞서 설명했듯, 공인 IP로 구분되는 네트워크 내에서만 사용되는 IP주소이다. 오로지 그 네트워크 안에서 서로를 구분하기 위해 사용되기 때문에, 네트워크가 다른 호스트라면 사설 IP 주소가 겹쳐도 상관 없다(물론 같은 네트워크 내의 호스트라면 겹치면 안됨). "김부추"와 "한부추"는 이름이 모두 "부추"로 같지만, 성이 다르기 때문에 구분된다. 여기서 성씨가 공인 IP, 이름이 사설 IP라고 말할 수 있겠다!!
사설IP로 사용 가능한 IP 범위는 다음과 같다. 각 클래스의 IP 주소에서, 사설 IP 사용가능 범위는 공인IP로 지정되어선 안된다.
| 클래스 | 사설 IP 사용가능 범위 |
| A | 10.0.0.0 ~ 10.255.255.255 |
| B | 172.16.0.0 ~ 172.31.255.255 |
| C | 192.168.0.0 ~ 192.168.255.255 |
지금 와이파이를 이용해서 글을 적고 있는데, 내 사설 IP주소를 확인해보기 위해 터미널 창에 아래 명령어를 입력해보았다.
$ ipconfig getifaddr en0결과로 클래스 C 범위의 사설IP주소가 할당된걸 확인할 수 있다!
192.168.0.9외부 통신에 사용되는 공인IP도 확인해보자.
$ curl ifconfig.me결과는..
218.238.67.64
그래. 같은 공인IP를 가진 네트워크 안에서 서로를 사설IP로 구분짓는다는 개념은 알겠다. 그런데 만약 네트워크 내의 호스트가 네트워크 바깥의 인터넷에 연결하고 싶을땐 어떻게 해야할까? 바깥 네트워크 참여자가 어떻게 내부 네트워크 참여자들을 구분할 수 있을까? 이때 사용하는 것이 NAT(Netwokr Address Translation)을 통한 IP주소 변환이다.
2-4) NAT : 사설IP와 공인IP간 변환
네트워크 단위의 게이트웨이 역할을 하는 라우터나 L3 스위치 등의 기기는 공인 IP 주소를 가진다. 이 게이트웨이의 역할이 막중하다. 하나의 네트워크 단위를 가지고 있는 게이트웨이는, 네트워크 내부의 호스트가 인터넷 연결을 하려고 할 때 해당 호스트의 사설 IP주소를 자신의 공인 IP주소로 변환하여 네트워크에 참여하도록 한다. 이 때, 이 IP 변환 기록을 자체적으로 가지고 있어 인터넷에서 해당 요청에 대한 응답이 오면 응답 데이터를 직전 요청 호스트의 사설 IP주소로 되돌려보낸다.
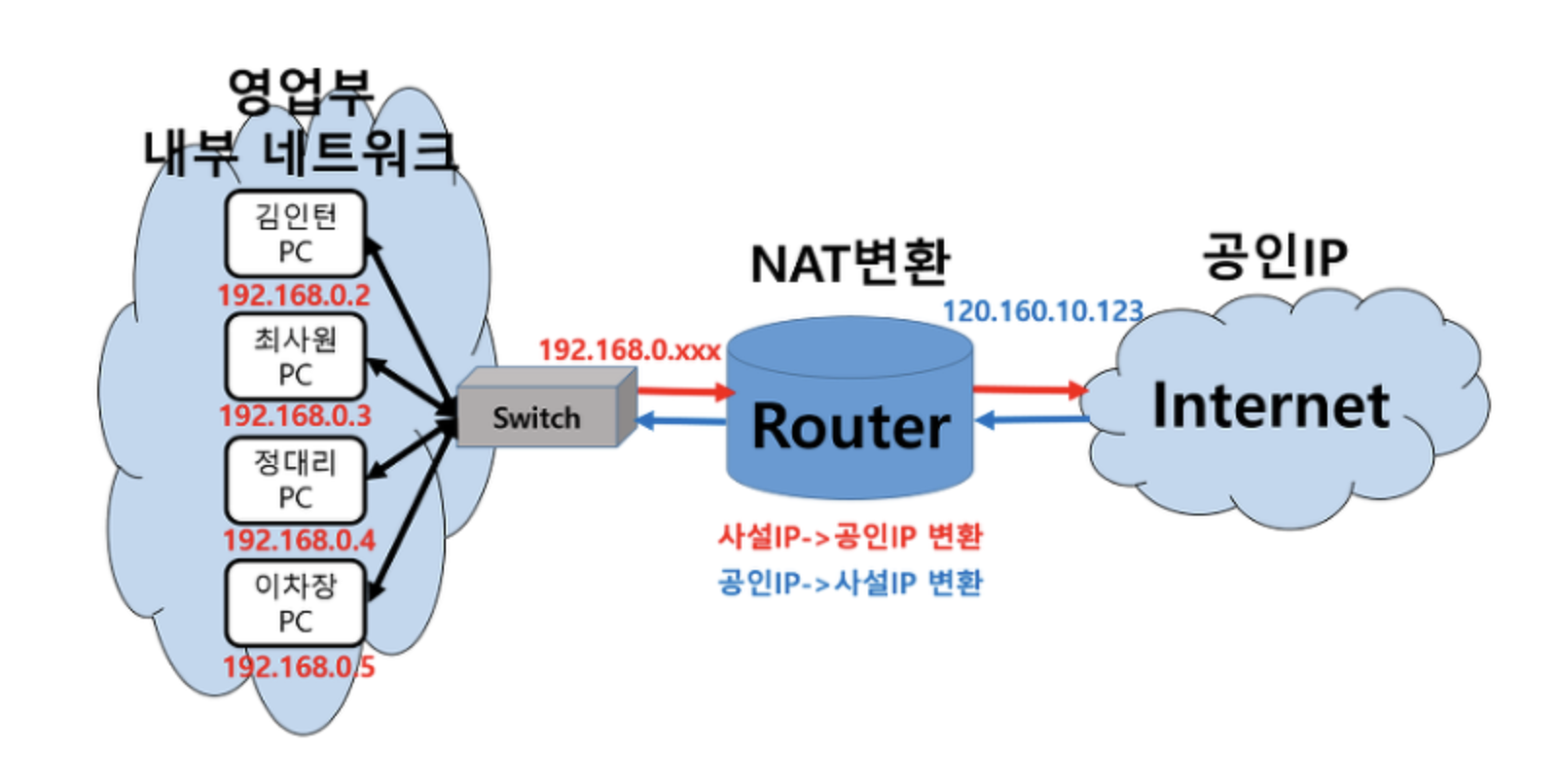
위 그림에서, 192.168.x.x의 사설 IP주소를 가진 영업부 내부 네트워크의 사람들은 통신을 위해 NAT 변환을 거쳐 120.169.1.123이라는 가면을 쓰고 인터넷에서 활동한다.
그런데 만약, 네트워크 내의 호스트들이 같은 포트를 이용해 인터넷 연결을 요청하면 어떻게 될까? 응답자는 둘을 어떻게 구분할까?
위 그림의 예시에서 김인턴과 최사원의 인터넷 브라우저가 모두 49152번 포트를 이용해 인터넷에 접근을 하는 상황이라면, 단순히 IP주소를 스위치의 공인 IP주소로 바꾼다 해서 두 호스트가 구분되지 않는다. 이땐 NAPT라는, NAT에 Port가 추가된 방법을 이용한다. 최사원의 프로세스가 사용하는 기존의 49152번 포트를 49153번으로 바꾸면 최사원과 김인턴의 요청이 구분된다. 게이트웨이는 이 포트 변환 기록을 기록해뒀다가 각각의 포트에 대한 응답이 들어왔을 때 이를 구분해서 최사원과 김인턴에게 되돌려줄 수 있다.
그렇다면 네트워크 바깥에서 먼저 요청이 들어온 경우엔 어떻게 해야할까?
일단 네트워크 내부 호스트가 자체적으로 계속 요청을 보내는 방법을 사용할 수 있다. 올지도 모르는 응답을 위해 대기하는 것이 아니라, 계속 바깥에 "요청있어?" "요청있어?"하고 자기가 먼저 질문을 하는 것이다.
또한 포트포워딩이라는 방법을 사용할 수 있다. 네트워크 내에 80번 포트를 사용해 HTTP 요청을 받는 웹 서버가 있을 경우, 외부에서 80번 포트로 들어오는 요청은 해당 웹 서버로 전달될 수 있도록 하는 것이다. 특정 포트로 들어온 요청을 특정 호스트로 전달함으로써 외부 요청에 대응하는 것이 포트포워딩이다. 외부에서 먼저 들어오는 요청은 이런 서버에 대한 요청이 많고, 서버 역할을 하는 프로그램은 네트워크부 내에 한정되어 있으므로 이같은 동작이 가능하다.
2-5) DHCP : IP 주소 동적 할당
네트워크에 새로 참여하는 호스트가 있을 경우, 호스트에게 새로운 IP 주소를 할당해주어야 한다. 대부분의 경우 이 과정이 자동으로 이뤄지는데 이때 사용되는 것이 DHCP(Dynamic Host Configuration Protocol)이다. 보통 공공 와이파이나 가정용 인터넷 라우터들이 갖추고 있는 기능이다.
- 네트워크에 신규 호스트가 참여한다. 이 때, 브로드캐스트 방식으로 네트워크의 모든 호스트에게 DHCP 발견 패킷을 보낸다.
- 이를 받은 DHCP 서버는 새로운 호스트에게 할당할 IP 주소를 선택하고, 이 정보를 브로드캐스트 방식으로 네트워크의 모든 호스트에게 보낸다.
- 신규 호스트를 제외한 호스트들은 해당 패킷을 버린다. 신규 호스트는 그 패킷을 받고, 자신의 IP주소를 패킷에 적힌 주소로 설정한다.
DHCP 발견과 IP주소 할당 패킷을 브로드 캐스팅 방식으로 보내는 이유는, 새롭게 참여하는 호스트를 구분하여 그 호스트에만 패킷을 전달할 방법이 없기 때문이다. 참고로 브로드 캐스팅에 사용되는 IP주소는 호스트부의 비트가 모두 1인 192.168.1.1이다.
3. URL과 도메인 : IP 주소의 또다른 이름
어떤 웹 서버에 접속하기 위해, 43억개나 되는 IP주소를 사람이 모두 기억하거나 관리할 수 없다. 때문에 실제 사용자의 웹 서버 통신에선 32비트의 IP주소 대신 영어로 된 도메인 주소가 포함된 URL을 이용하게 된다. URL이 뭘까? 도메인 주소는 뭘까?
3-1) URL : 자료를 구분하기 위한 문자열
URL(Uniform Resource Locator)은 일상생활에서도 많이 사용하는 단어이다. 인터넷 브라우저를 통해 특정 웹사이트에 접속할 때 URL을 입력하기도 하고, 재미있는 글을 읽었을 때 해당 페이지의 URL을 친구에게 보내 공유하기도 한다. 이렇듯 URL을 이용하면 네트워크에서 이용하는 자료를 구분할 수 있다. 어떤 URL을 가진 웹 페이지는 유일하므로, URL은 인터넷 자원을 식별할 수 있도록 하는 URI의 한 종류이다.

- scheme : 통신에 사용하는 프로토콜이다. 브라우저를 통한 웹 통신은 HTTP, HTTPS를 주로 사용한다.
- hosts : 네트워크 통신을 통해 접근할 상대방의 도메인 주소. 도메인 주소(google.com) 앞에 호스트명(www)이 오는 구조인데 한 번에 도메인명이라고 부르기도 한다.
- url-path : 접근 대상에 대한 상세 경로
- query : 필수는 아니며, 요청의 query parameter로서 서버가 받을 수 있는 정보
어. 지금까지 설명하길 통신 목적지를 찾아가기 위해선 IP 주소가 필요하다 했던 것 같은데, IP 주소는 어디가고 '도메인 주소'라는 놈이 나왔나? 싶다. 사실 이 도메인 주소가 바로 IP 주소이다. 정확히 말하면 도메인 주소를 IP 주소로 매핑하는 과정이 일어난다고 할 수 있다.
3-2) DNS : 도메인명과 IP 매핑
DNS(Domain Name System)은 URL에 사용되는 서버 식별자인 도메인 이름과 IP 주소를 매핑하는 시스템이다. 앞서 언급했듯, 사람이 32비트의 IP주소를 직접 이용해 통신하기는 직관성이 떨어지니 URL엔 외우고 사용하기 쉬운 도메인 이름이 사용된다. 이 도메인 이름 자체는 네트워크 상에서 컴퓨터를 구분짓는데 사용되진 못하고, 이를 IP 주소로 바꿔주는 시스템이 필요하다. 여기서 필요한 것이 DNS 서버이다.
100% 일치하진 않지만, 도메인 이름과 DNS 서버는 계층 구조로 이루어져 있다. 도메인 이름에서 "."으로 구분되는 항목들 중 가장 뒤에 있는 것이 상위, 한 단계씩 앞으로 갈수록 하위(혹은 서브) 도메인이다.
"www.google.com"이라는 도메인과 "support.google.com"이라는 도메인을 생각해보자. ".com"은 최상위 도메인이다. google은 그 밑의 2차 도메인, www와 support는 그 하위에 있는 3차 도메인이다. 만약 "google.com"이라는 도메인 이름을 구매했다면 해당 도메인의 하위 호스트인 "www.google.com"과 "support.google.com" 역시 이용할 수 있다.(서버 컴퓨터와 해당 컴퓨터의 IP 주소가 존재한다면 말이다)
특정 도메인의 IP 주소를 얻기 위해 DNS에 질의를 하는 과정 역시 계층적으로 일어난다. 같은 도메인으로 예시를 들겠다. 아래 그림을 참고하여 root DNS 서버 -> .com DNS 서버 -> google DNS 서버를 거쳐 "www.google.com"의 IP 주소가 응답되는 과정을 상상하자.
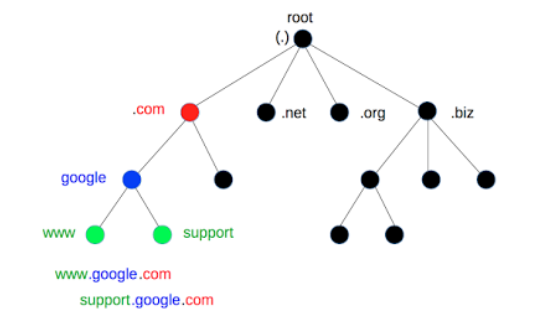
- 가장 먼저 로컬DNS 서버로 "www.google.com"에 대한 DNS 질의가 들어온다.
- 로컬 DNS 서버는 자신이 가지고 있는 DNS 캐시를 확인한 후 해당 IP 주소가 있을 시 결과를 응답한다.
- DNS 서버에 해당하는 IP주소가 없을경우, root DNS 서버에 질의한다. root DNS 서버는 최상위 도메인 "com"에 대한 DNS 서버 주소를 응답으로 보낸다.
- 응답받은 "com" DNS 서버에 질의한다. "com" 서버는 "google.com"에 대한 DNS 서버 주소를 응답으로 보낸다.
- 응답받은 "google.com" DNS 서버에 질의한다. 결과가 해당 DNS 서버에 있으면 IP주소를 응답한다.
대충 계층적으로 이뤄진 도메인 이름에 대해 계층적으로 DNS 서버에 질의하는 과정이 그려질 것이다. 그림으로 정리하면 아래와 같다. 아래는 "beta.example.com"이라는 도메인의 IP주소를 질의하는 예시이다.
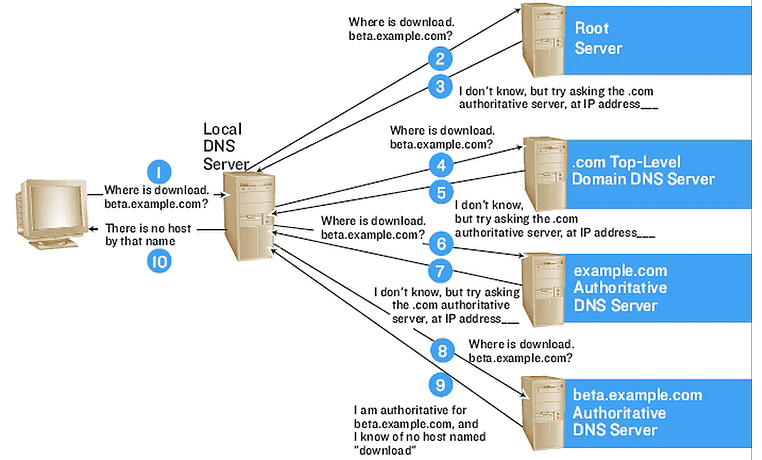
DNS가 필요할 때마다 전세계의 컴퓨터들이 root DNS 서버들에게 질의를 하는 것은 비효율적이다. 따라서 로컬 DNS 서버나 도메인 이름을 통해 서버 통신을 시도하는 네트워크 기기들엔 많은 DNS 캐시들이 존재한다.
4. 라우팅
이제 IP 프로토콜을 통해 실제로 패킷이 출발지에서 목적지까지 가는 과정에 대해 알아보자. 이 과정 중 가장 중요한 것은 당연 라우터이다(포트포워딩과 NAT에서도 중요했는데.. 라우터 이자식)
출발지에서 시작한 패킷은 출발지 네트워크와 가장 가까운 라우터에 도착한다. 라우터는 패킷의 IP 주소를 확인하고, 해당 주소에 맞는 다음 라우터에게 패킷을 전달한다. 패킷을 전달받은 다음 라우터는 또다시 패킷의 IP 주소를 확인하고 해당 주소에 맞는 다음 라우터에게 패킷을 또다시! 전달한다. 패킷이 목적지 네트워크에 도착할 때까지 라우터 -> 라우터 -> 라우터 -> ... 의 과정을 반복한다.
이를 위해 라우터에는 라우터와 직접 연결된 다른 라우터들, 혹은 호스트들의 IP 주소를 가지고 있어야 한다. 그리고 [특정 IP주소 - 해당 IP 주소를 가진 패킷을 전달할 다음 라우터] 쌍을 가져야 하는데, 이를 "라우팅 테이블"이라고 한다. 그리고 당연히, 라우팅 테이블의 row 개수는 최소한 연결된 라우터 개수 이상이어야 한다. 라우팅 테이블에 패킷의 목적지 IP 주소가 없는 경우를 대비해 각 라우터에는 디폴트 라우터(0.0.0.0/0)가 존재해, 해당 패킷을 디폴트 라우터로 전달한다.
라우팅 테이블을 설정하는 방법에는 정적 라우팅과 동적 라우팅 두 가지가 있는데, 라우팅 테이블이 한 번 설정된 뒤 바뀌지 않는 정적 라우팅은 거의 쓰이지 않는다. 동적 라우팅은 실시간으로 네트워크의 상태를 파악하고 패킷에게 최적의 경로가 되는 방향으로 라우팅 테이블을 업데이트하여 전달한다. 이렇게 라우팅 테이블을 구성하기 위한 프로토콜엔 어떤 것들이 있을까?
4-1) RIP (Routing Information Protocol)
단순히 현재 패킷의 목적지까지의 거리를 살펴보고 가장 짧은 거리를 안내하는 방식이다. 이 때 사용되는 거리는 "홉"이라는 단위로, 목적지까지 경유하는 라우터의 수를 의미한다.
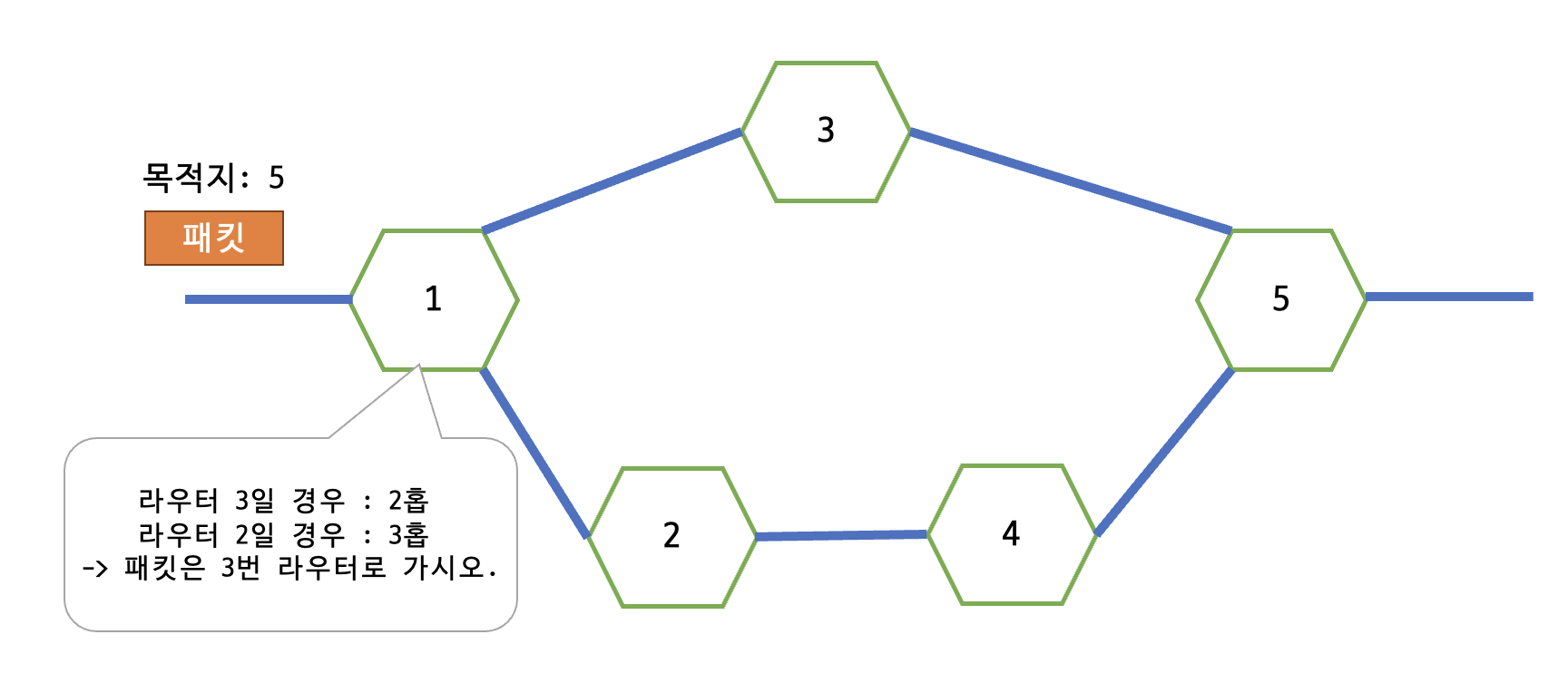
위 그림에서, 왼쪽 패킷의 목적지가 라우터 5번이라고 하면 5번으로 가기 위한 방법은 1->3->5, 1->2->4->5 두 가지가 있다. 첫 번째의 방법이 2홉으로 더 빠르므로 라우터는 패킷을 3번 라우터로 보낸다.
4-2) OSPF (Open Shortest Path First)
역시 목적지까지의 거리를 고려하여 최적의 경로를 안내하지만, 단순히 홉의 개수가 아니라 상태가 가장 좋은 경로를 선택한다.
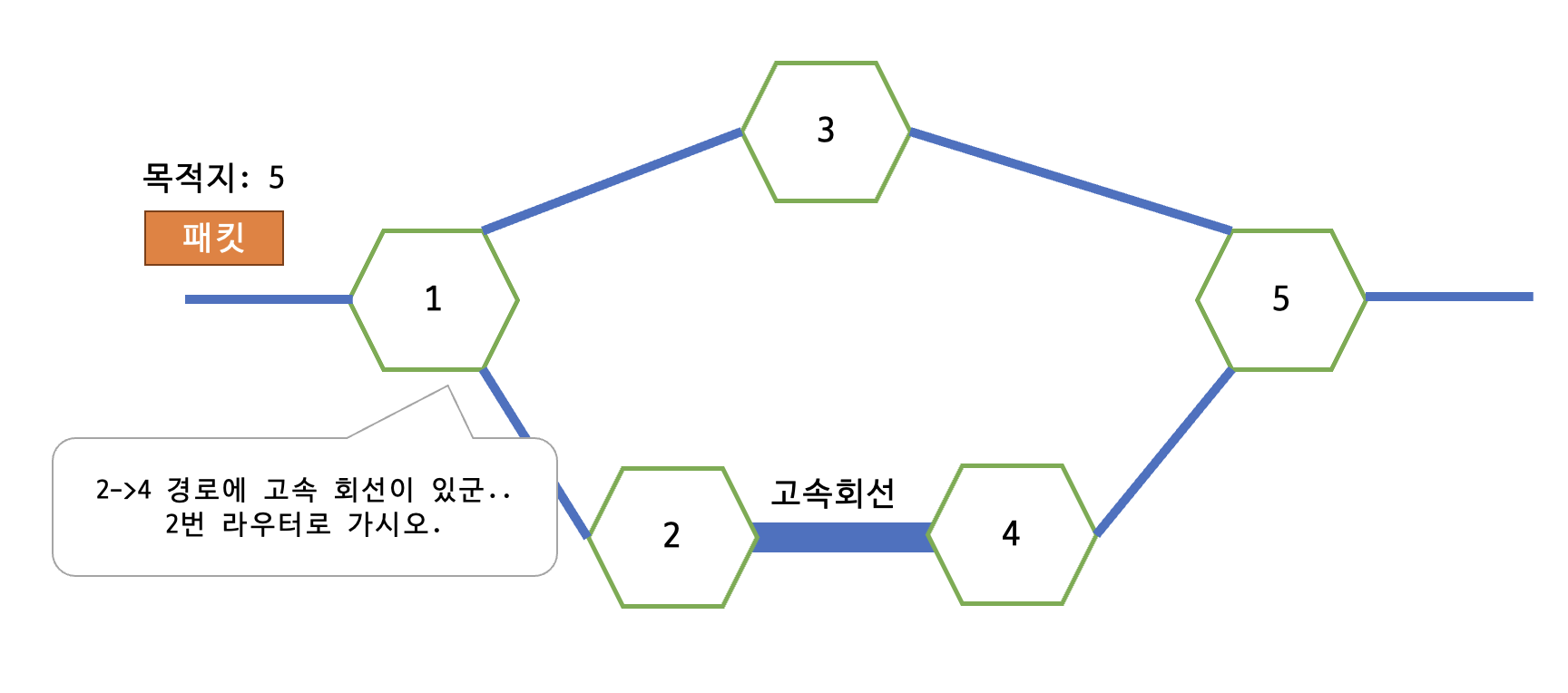
위의 그림은 기본적으로 RIP와 같은 상태이지만, 라우터 2->3의 경로가 고속회선으로 대체되어있다. 고속 회선을 이용할 경우, 3번 라우터를 선택하는 것에 비해 라우터를 한 번 더 거쳐야 하지만
라우터는 고속 회선을 포함해 네트워크 혼잡 등의 통신 상태 정보를 맵 형태로 관리한다. 이 정보를 이용해 실시간으로 패킷에게 최적의 경로를 안내하여, 복잡하고 변화가 잦은 네트워크 구성에 많이 이용된다.
4-3) BGP (Border Gateway Protocol)
논리 자체는 RIP와 비슷하다. 홉수를 고려해서 패킷에게 다음 라우터를 안내한다.
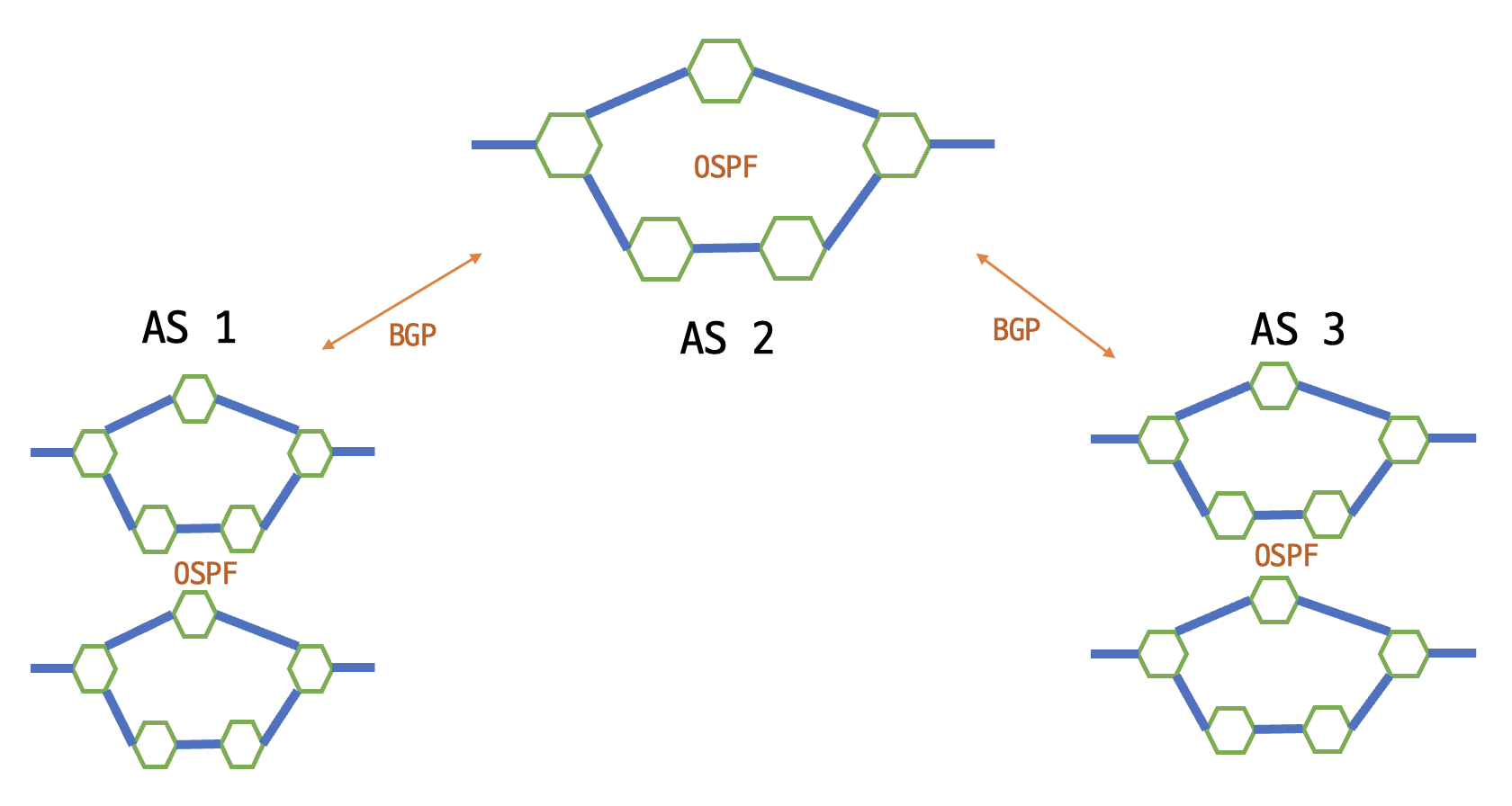
앞선 두 프로토콜(RIP, OSPF)은 하나의 라우터 무리 안에서(AS, Autonomous System) 패킷을 전달하기 위해 사용하는 프로토콜이다. 그러나 BGP는 다른 AS 사이에 패킷을 전달하기 위해 사용한다는 특징이 있다.
REFERENCE
https://cheershennah.tistory.com/178
https://almotjalal.tistory.com/98
https://hwan-shell.tistory.com/320