
프로젝트에서 localhost에 띄운 MySQL을 사용하고 있습니다~ yml파일 모습입니다. h2는 레코드의 r/w연산에 대해 테이블 단위로 락을 거는 기본 동작을 사용합니다..
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/market?useSSL=false&serverTimezone=Asia/Seoul&characterEncoding=UTF-8
username: root
jpa:
hibernate:
ddl-auto: update
# 상황 : 100명의 구매자가 100개가 존재하는 상품을 1개씩 구매
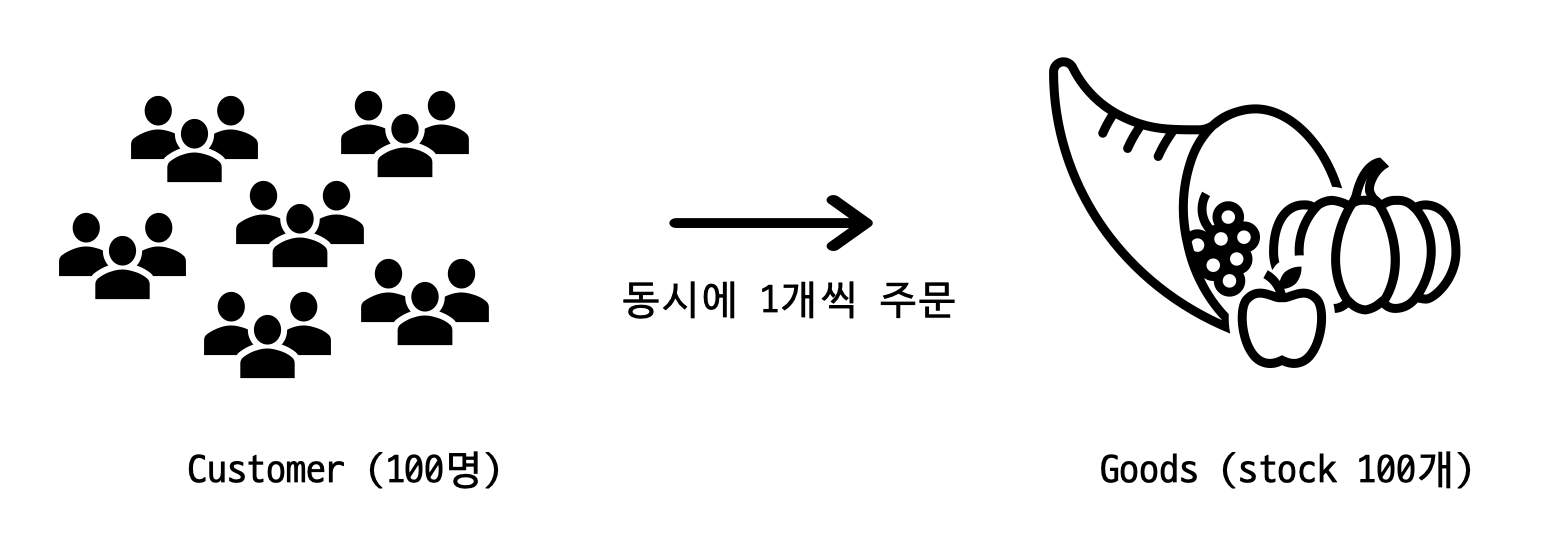
Customer 클래스 인스턴스인 구매자 100명이 각각 1개의 스레드가 되어 재고가 100개인 상품을 동시에 1개씩 구매하려고 한다. Customer와 Goods는 모두 name 필드를 가지며, Goods는 재고를 나타내는 int stockNumber라는 클래스 변수를 가지고 있다. Spring Data JPA의 JpaRepository에 의한 CRUD가 가능하다고 하고, 별다른 동시성 처리를 해주지 않은 buyGoodsWithoutLock() 메소드 코드는 아래와 같다.
@Service
@Slf4j
@RequiredArgsConstructor
public class MarketService {
private final CustomerJpaRepository customerJpaRepository;
private final GoodsJpaRepository goodsJpaRepository;
/**
* customer가 number 개수의 goods를 구매한다. 별다른 동시성 제어를 하지 않는다.
* @param customerName 구매자 이름
* @param goodsName 상품 이름
* @param number 상품 개수
*/
@Transactional
public void buyGoodsWithoutLock(String customerName, String goodsName, int number) {
Customer customer = customerJpaRepository.findByName(customerName)
.orElseThrow(EntityNotFoundException::new);
Goods goods = goodsJpaRepository.findByName(goodsName)
.orElseThrow(EntityNotFoundException::new);
customer.buy(goods, number);
log.info("{} 님이 {}를 {}개 구매하셨습니다.",
customer.getName(),
goods.getName(),
number);
}
}그냥 1. DB에서 customer, goods를 이름으로 찾은 뒤 2. 구매자가 number만큼의 goods를 구매한다. 3. 로그를 찍는다. Customer과 Goods의 엔티티 코드는 다음과 같다. buy()와 decreaseStock()은 Goods의 필드값을 단순히 감소시킨다는 점에서 직관적이다.
@Entity
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
@NotBlank
@Length(max = 30)
private String name;
public void buy(Goods goods, int number) {
goods.decreaseStock(number);
}
}
@Entity
public class Goods {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
@NotBlank
@Length(max = 30)
private String name;
@Column
private int stockNumber;
/**
* stockNumber만큼 현재 상품의 재고를 감소시킨다.
* @param stockNumber
*/
public void decreaseStock(int stockNumber) {
isAvailable(stockNumber);
this.stockNumber -= stockNumber;
}
/**
* required 이상의 재고가 존재하는지 검증한다.
* @param required
*/
private void isAvailable(int required) {
if (required > stockNumber) {
throw new NotEnoughStockException(name);
}
}
}
이제 실제로 테스트 코드를 돌려보자.
@SpringBootTest
public class RaceConditionTest {
@Autowired
private CustomerJpaRepository customerJpaRepository;
@Autowired
private GoodsJpaRepository goodsJpaRepository;
@Autowired
private MarketService marketService;
@BeforeEach
public void setUp() {
customerJpaRepository.deleteAll();
goodsJpaRepository.deleteAll();
}
@Test
@DisplayName("동시성 제어 없이 레코드를 수정하면 race condition이 발생한다.")
public void raceConditionTest() throws InterruptedException {
// given : 구매자 100명과 재고가 100개인 대파가 존재한다.
List<Customer> customers = IntStream.range(0,100)
.mapToObj(i -> Customer.builder().name("구매자" + i).build())
.map(customer -> customerJpaRepository.save(customer)).toList();
Goods leek = goodsJpaRepository.save(
Goods.builder().name("대파").stockNumber(100).build());
CountDownLatch countDownLatch = new CountDownLatch(100);
// when : 구매자 100명이 lock 없는 메소드를 통해 동시에 대파를 구매한다.
List<Thread> threads = customers.stream().map(
customer -> new Thread(() -> {
marketService.buyGoodsWithoutLock(
customer.getName(), leek.getName(), 1);
countDownLatch.countDown();
})).toList();
threads.forEach(Thread::start);
countDownLatch.await();
// then : 재고가 0개가 아니다.
goodsJpaRepository.findByName("대파").ifPresent(
goods -> assertNotEquals(0,goods.getStockNumber()));
}
}"구매자0"부터 "구매자99"를 DB에 생성하고, "대파" 상품을 100개 생성한다. 그리고 100명의 각 구매자가 재고가 100개인 대파를 1개씩 구매하는 thread 리스트를 만들고, 각각을 동시에 실행시키며 CountDownLatch를 통해 모든 스레드의 실행이 끝나길 기다린다.
100명이 100개를 1개씩 구매했으므로, 상품의 재고는 0개가 되어야 한다. 상품의 재고를 assertNotEquals()를 통해 0개와 같지 않다는 것을 검증한다고? 당연히 실패할 것이다.
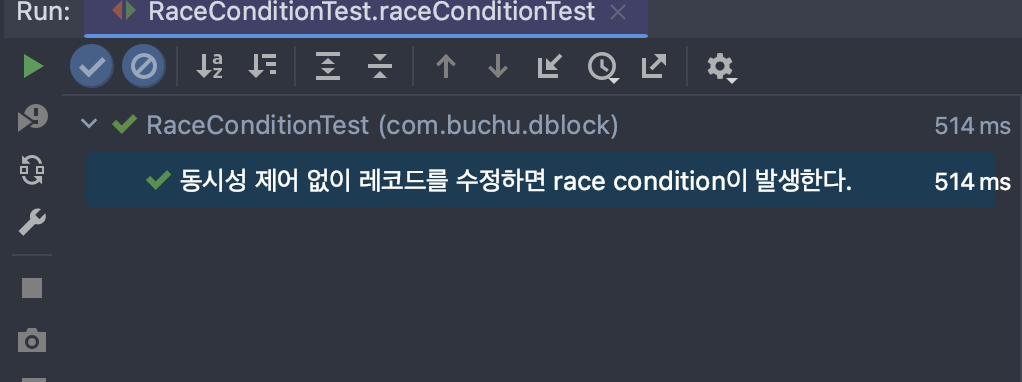
응 아니야~~ 재고 0개 아니야~
# 동시성 문제 : non-repeatable read
buyGoodsWithoutLock()이 DB의 상품 데이터를 읽고 재고를 감소시키는 로직은 DB 서버에 날리는 쿼리 기준으로 다음과 같은 단계를 거친다.
- 상품 데이터의 stock_number 필드를 읽는다.
- stock_number 필드 값을 구매하고자 하는 number만큼 감소시킨다.
그러나 여러 스레드가 동시에 1,2번을 진행한다고 가정해보자. 100개의 재고, 구매자1이 10개의 대파를, 구매자2가 10개의 대파를 구매하려는 상황이다. 모든 스레드의 실행이 종료되면 대파의 stock_number 값은 80이 되어야 할 것이다.
- 구매자1이 대파의 stock_number 필드를 100으로 읽는다.
- 구매자2가 대파의 stock_number 필드를 100으로 읽는다.
- 구매자1이 대파의 stock_number 필드를 90으로 업데이트 한다.
- 구매자2가 대파의 stock_number 필드를 90으로 업데이트 한다.
그러나 결과는 90. 각 단계를 따라가보니 무엇이 문제인지 잘 보인다. 현재 데이터를 수정하려는 트랜잭션이 다른 트랜잭션이 수정중인 데이터를 읽었기 때문에 이런 동시성 문제가 발생하는 것이다. 원인을 알았으니 해결법은 간단하다. 데이터를 수정하려는 트랜잭션은 해당 데이터가 수정중일 때, 다른 트랜잭션이 데이터에 접근할 수 없도록 하면 된다. 이를 전문적 용어로 하면 배타락을 건다, 라고 할 수 있다.
DB에서 여러 스레드가 레코드에 접근했을 때, 동시성 컨트롤을 어떻게 하는지 설명하기 위해 간단한 용어 설명을 해보겠다.
# s-Lock(공유 락)과 x-Lock(배타락)
공유락은 간단하게 말하면 특정 트랜잭션이 획득한 락의 레코드에 다른 트랜잭션이 쓰기 연산을 할 수 없도록 하는 락이다. 트랜잭션 T1이 공유락을 걸고 특정 데이터를 읽는 동안 다른 트랜잭션 T2가 데이터를 수정하려고 하면 T1이 락을 놓을 때까지 대기해야할 것이다. 배타락은 특정 트랜잭션이 배타락을 획득했을 때, 다른 트랜잭션이 해당 레코드에 접근할 수 없게 하는 락을 뜻한다. 여기서 접근이란 읽기와 쓰기 연산 모두 포함이다. 만약 다른 트랜잭션이 배타락이 걸린 레코드에 접근한다면 락이 풀릴 때까지 대기해야 한다.
# 낙관적 락
JPA에서 낙관적 락은 락이라기보단.. 버저닝을 통한 데이터 충돌 방지라고 할 수 있겠다. Repository에서 데이터를 읽어올 적에 @Lock의 LockModeType을 Optimistic으로 두면 되는데 이렇게 되면 여러 트랜잭션이 동일한 리소스를 write할 경우 예외가 난다. 트랜잭션 데이터에 버저닝을 하는 것으로 이를 구현한다. 어떤 트랜잭션이 write 연산을 수행한 뒤 commit 성공하면 해당 레코드의 버전이 update되는데, 다른 트랜잭션이 똑같이 write를 시도했지만 레코드 버전이 다를 때 ObjectOptimisticLockingFailureException가 던져진다. 간단한 설명을 들었으니 알겠지만.. 낙관적 락은 어플리케이션이나 DB 서버 측에서 동시성 관리를 한다기보단 단순히 충돌된 접근에 예외만 던지는 것으로 끝나기 때문에 글 초반에 설명했던 문제상황의 해결책으로는 적절하지 않아 보인다. 충돌이 거의 없을거라고 가정하는 상황에서 혹시 모를 충돌이 존재할 때 예외를 던지는 기법이다~ 정도로 낙관적 락을 이해하자.
# 비관적 락
비관적 락은 트랜잭션 데이터 접근시에 아예 락을 걸고 시작하는 방법이다. 이 때 락은 (당연하게도) X-Lock이며 배타락을 걸고 시작한 레코드는 다른 트랜잭션이 읽을 수도, 쓸 수도 없다. Repository의 쿼리 메소드에 @Lock 어노테이션과, LockModeType 옵션을 설정하면 해당 메소드를 락을 필요로 하는 메소드로 설정할 수 있다.
public interface GoodsJpaRepository extends JpaRepository<Goods,Long> {
Optional<Goods> findByName(String name);
/**
* 조회하는 레코드에 락을 걸어 race condition을 타파한다.
* PESSIMISTIC_READ : 조회되는 레코드에 공유락을 건다.
* PESSIMISTIC_WRITE : 조회되는 레코드에 배타락을 건다.
* @param name 상품 이름
* @return
*/
@Lock(LockModeType.PESSIMISTIC_WRITE)
Optional<Goods> findWithLockByName(String name);
}트랜잭션에서 가져온 데이터에 비관적(PESSIMISTIC) 락을 걸 수 있는 옵션은 다음과 같다. 해당 락 설정은 트랜잭션 메소드가 commit되거나 rollback 될 때 해제된다.
- PESSIMISTIC_READ : 레코드에 공유락(s-Lock)을 건다. 다른 트랜잭션은 읽기 연산만 가능하다.
- PESSIMISTIC_WRITE : 레코드에 배타락(x-Lock)을 건다. 다른 트랜잭션은 해당 데이터에 대한 읽기/쓰기 연산 모두 불가능하다.
- PESSIMISTIC_FORCE_INCREMENT : 레코드에 배타락을 걸면서도 레코드에 버전을 추가한다. 여기서 버전이란 낙관적 락에서 사용한 것과 같다.
문제 상황에선 1. 상품 재고가 얼마나 남아있는지 확인해야하고(만약 원하는 개수 미만이라면 구매 불가) 2. 상품 재고를 원하는 개수만큼 차감시킨다. 1번에서 읽는 데이터에 대해서도, 그리고 2번에서 작성하는 데이터에 대해서도 다른 트랜잭션들과 분리되어야 하므로 buy() 메소드 시작 시점에 배타락을 얻는 것이 맞다. 때문에 @Lock(LockModeType.PESSIMISTIC_WRITE)옵션을 사용했다.
해당 쿼리를 사용한 서비스 메소드를 추가했다.
/**
* customer가 number 개수의 goods를 구매한다.
* 배타락을 통해, 아래 트랜잭션이 레코드 락을 획득한 이후엔 다른 트랜잭션의 RW 접근이 불가하다.
* @param customerName 구매자 이름
* @param goodsName 상품 이름
* @param number 상품 개수
*/
@Transactional
public void buyGoodsWithLock(String customerName, String goodsName, int number) {
Customer customer = customerJpaRepository.findByName(customerName)
.orElseThrow(EntityNotFoundException::new);
Goods goods = goodsJpaRepository.findWithLockByName(goodsName)
.orElseThrow(EntityNotFoundException::new);
customer.buy(goods, number);
log.info("{} 님이 {}를 {}개 구매하셨습니다.",
customer.getName(),
goods.getName(),
number);
}기존과 달라진 점은 findByName()이 findWithLockByName()으로 바뀌었다는 점 뿐이다. 이제 buyGoodsWithLock()를 사용하는 서비스 메소드를 테스트해보자.
@Test
@DisplayName("배타락을 통해 동시성 이슈를 해결한다.")
public void pessimisticLockTest() throws InterruptedException {
// given : 구매자 100명과 재고가 100개인 대파가 존재한다.
List<Customer> customers = IntStream.range(0,100)
.mapToObj(i -> Customer.builder().name("구매자" + i).build())
.map(customer -> customerJpaRepository.save(customer)).toList();
Goods leek = goodsJpaRepository.save(
Goods.builder().name("대파").stockNumber(100).build());
CountDownLatch countDownLatch = new CountDownLatch(100);
// when : 구매자 100명이 PESSIMIST_WRITE 락이 필요한 트랜잭션 메소드를 사용한다.
List<Thread> threads = customers.stream().map(
customer -> new Thread(() -> {
marketService.buyGoodsWithLock(
customer.getName(), leek.getName(), 1);
countDownLatch.countDown();
})).toList();
threads.forEach(Thread::start);
countDownLatch.await();
// then : 재고가 0개다.
goodsJpaRepository.findByName("대파").ifPresent(
goods -> assertEquals(0,goods.getStockNumber()));
}then이 성공했을까?
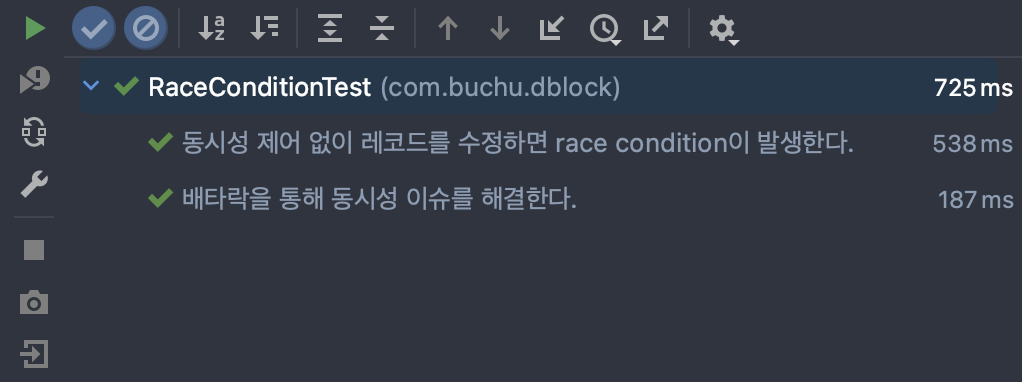
넴 ^-^. 재고를 확인하고 업데이트하는 일련의 과정동안 배타락을 들고 다른 트랜잭션의 접근을 막으니 동시성 문제가 해결되었다! 하지만 락은 강력한 동시성 컨트롤을 해주는 만큼 DB 스레드의 효율적 운용을 방해하므로, 데이터의 일관성이 중요한 메소드에서만 사용하도록 하자. 대부분의 READ 연산에서는 비관적 락은 물론, s-Lock마저 필요하지 않을 수 있다..(아..닌가..?) 물론 글을 보면 MySQL 측에선 연관 관계가 있는 엔티티 row에는 읽을 때 무조건적으로 s-Lock, 쓸 때는 x-Lock을 거는 듯 하다.
지금까지 설명했던 것과는 조금 결이 다른 내용인데 DB 엔진 자체에서 서로다른 두 트랜잭션 사이에 읽기-쓰기 연산이 충돌한다고 했을 때, 두 트랜잭션의 격리 수준에 따라 이를 어떻게 처리하는지 트랜잭션 격리 레벨? 격리 수준? 고립 레벨? 고립 수준?을 간단하게 정리해보자. 자세한 내용은 이쪽!
# 트랜잭션 isolation level
트랜잭션 격리 레벨, 고립 수준 .. 등등으로 번역되는 isolation level은 다른 트랜잭션이 수정중인 데이터에 어떻게 접근할 것인지, 수정중인 트랜잭션 - 읽으려는 트랜잭션 사이의 격리를 어떤 수준으로 설정할 것인지 4단계로 나눈 결과다.
1. LEVEL0 : READ UNCOMMITTED
직역한 그대로다. 커밋되지 않은 데이터도 읽을 수 있게 한다. 트랜잭션 T1이 어떤 데이터에 UPDATE 쿼리를 날리는 즉시 다른 트랜잭션 T2는 UPDATE된 레코드를 읽는다. 만약 T1 수행중 예외가 발생해서 롤백이 되면 T2는 같은 쿼리에 대해 다른 결과를 돌려받게 된다. 사실상 트랜잭션 간 격리는 없다고 보면 된다.
2. LEVEL1 : READ COMMITTED
역시 직역한 그대로다. 커밋된 데이터만 읽을 수 있도록 한다. 그러나 이 격리수준 역시 커밋 이전에 읽은 데이터와 커밋 이후에 읽은 데이터는 불일치하기 때문에 같은 쿼리에 대한 결과가 다르다. 이를 두고 "non-repeatable read"문제라고 한다.
3. LEVEL2 : REPEATABLE READ
이것 또한 직역한 그대로다. repeatable read는 동일 트랜잭션 내에서라면 같은 쿼리에 대해 같은 결과를 보장하는 것을 의미하는데, REPEATABLE READ 수준의 격리에선 트랜잭션에 번호를 부여함으로써 이를 달성한다. 더 높은 번호를 가진 트랜잭션, 즉 나중에 실행된 트랜잭션의 결과는 더 먼저 실행된 트랜잭션의 입장에선 무시하는 것이다. 만약 뒤에 실행된 트랜잭션이 레코드를 변경시켰을 경우 앞선 트랜잭션은 "UNDO" 영역에 백업된 기존 버전의 레코드 데이터를 읽는다. MySQL InnoDB 기준 기본 설정이라고 하는데..
4. LEVEL3 : SERIALIZABLE
모든 트랜잭션 요청이 직렬화된다. 특정 레코드에 읽기/쓰기 등의 트랜잭션이 진행되고 있는 상황에서 다른 트랜잭션이 레코드에 접근하면 앞선 트랜잭션이 끝나기 전까지 대기하는 격리수준이다. 트랜잭션이 순서대로 진행되므로 가장 엄격한 격리수준이라고 할 수 있다. 그러나 엄격한 격리와 좋은 성능은 트레이드 오프 관계에 있으므로.. 진짜로 데이터 정합성이 중요한 상황이 아니라고 한다면 추천되는 접근은 아니다!
다음 글에서는 분산 + 멀티 스레드 환경에서 동시성 제어를 확실하면서도 간단하게 할 수 있는 레디스 분산락에 대해 정리해보겠다@!
# REFERENCE
https://sabarada.tistory.com/187
+) 상기한 링크들