
- 이 글은 배포 자동화에 대한 자세한 방법보단, 신입 입장에서 각각의 간단한 개념과 필요한 이유를 중점으로 다룹니다.
# 통합/배포란 무엇이며, 자동화가 필요한 이유
자바 개발자에 의해 작성된 .java 소스코드는 javac 컴파일러에 의해 .class 확장자를 가진 자바 바이트 코드로 변환된다. 바이트 코드는 하드웨어가 아니라 JVM이 실행할 수 있는 코드인데, JVM은 바이트 코드를 그대로 기계어로 번역하기도 하고, 여러번 실행되는 메소드 단위의 코드를 한번에 기계어로 컴파일하는 JIT 컴파일링 방식을 사용하기도 한다. 이렇게 컴파일된 코드는 java 명령어로 실행할 수 있다.
보통의 어플리케이션 코드는 프레임워크나 라이브러리가 제공하는 의존성 코드들을 어마어마하게 많이 가지고 있는데, 라이브러리를 포함한 어플리케이션 코드를 실행하기 위해선 당연히 라이브러리 역시 함께 컴파일되고 관리되어야 한다. 그런데.. 스프링 부트의 spring mvc, spring security, spring test만 봐도 의존성 파일 갯수가 수십개는 넘는다.
이걸 모두 개발자가 하나하나 경로를 설정하고 함께 컴파일 한다는 것은 말이 안된다. 그렇기 때문에 우리는 maven, gradle같은 빌드 도구를 이용한다. 빌드 도구란? 작성한 어플리케이션 소스 코드와 의존성 라이브러리를 통합하여 실행 가능한 하나의 자바 패키지 파일을 빌드할 수 있게 해주는 도구이다.
내가 프로젝트에 사용한 gradle의 경우, `build.gradle` 파일에 원하는 의존성과 버전을 입력하면 gradle이 의존성을 다운받아 프로젝트에 사용할 수 있게 설정해준다. 이런 의존성 관리 뿐만아니라 build, test, clean, jar 등 테스트, 사용자 정의 패키징까지 모두 가능하게 해준다. 의존성 코드들과 리소스까지 포함되어 java 명령어로 실행될 준비가 된 결과 패키징 파일을 Jar 파일이라고 부른다.
어플리케이션 개발자는 다음과 같은 과정으로 소스코드를 빌드하고 .jar 파일을 개발 서버에 배포할 수 있다.
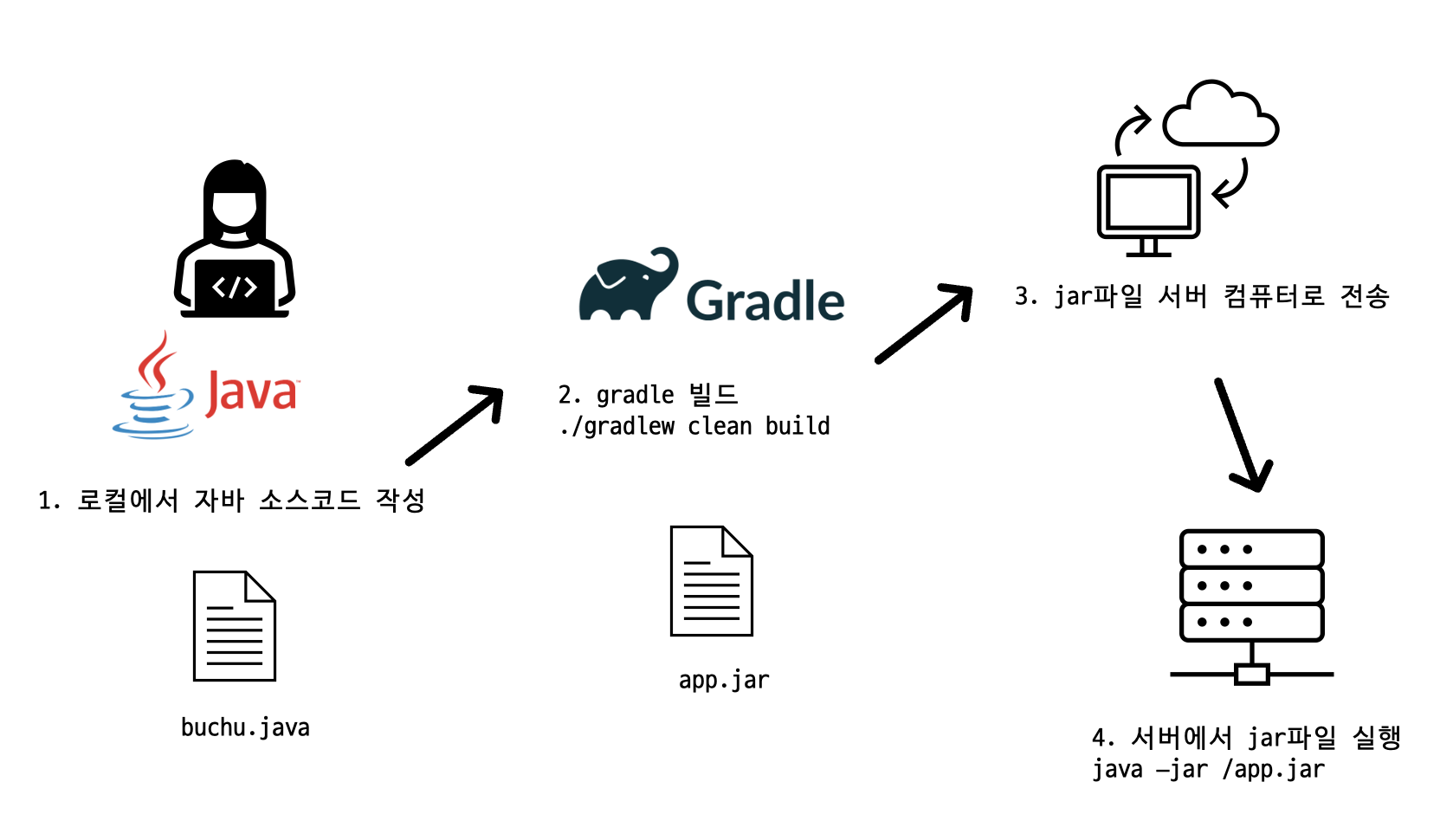
요컨데 로컬작성 -> 빌드 -> 서버전송 -> 서버실행 과정을 거치는 것이다.
gradle 명령어를 통해 프로젝트 소스코드와 라이브러리, 그리고 어플리케이션 실행에 필요한 리소스 등을 통합 빌드하는 과정을 통합(Integration), 그리고 통합된 파일을 서버에서 실행시키는 과정을 배포(Deploy)라고 한다.
어플리케이션은 한 번 개발하고 배포한 뒤 끝이 아니다. 운영 과정중 발생한 버그를 고쳐야 수도 있고, 클라이언트의 요청에 따라 새로운 기능을 추가하거나 수정해야할 수도 있다. 그러면 또다시 1번부터 시작이다. 소스코드를 새로 작성한다. 그리고 다시 build한다. 빌드 결과물을 서버 컴퓨터로 보내고, 서버에서 java 명령어를 통해 jar 파일을 실행시킨다.
코드의 배포가 자주 일어나면 위 과정만 수십번을 해야한다. 한 번 서버 컴퓨터에 ssh로 접속하는데도 몇십초가 걸리는데, 새로 코드가 작성될 때마다 위 과정을 거치는 것은 여간 귀찮은 일이 아니다. 팀으로 일할 경우, 코드 수정 및 통합/배포 주기는 더 빠르게 진행될 것이며 그때마다 위 과정을 반복해야한다. 실제로 서버에 위 과정을 통해 배포한 경험이 있다면 알겠지만,, 별로 어려울 것 없이 명령어만 치는 작업이 진짜 생각보다 시간 오래 걸린다.
우리는 수정한 코드를 푸시하면 자동으로 소스코드가 빌드되고, 서버에 배포되었으면 좋겠다. 그렇기 때문에 자동 통합/배포 파이프라인을 구성할 것이다.
# Docker에 관한 간단한 설명
66챌린지를 할 때 간단하게 설명했는데, 배포 자동화에 도커 컨테이너 배포 방식을 이용할 것이므로 한 번 더 설명하겠다.
Docker는 "컨테이너"라고 불리는 프로세스 단위의 격리 실행 환경을 제공한다. 마치 JVM이 존재하는 컴퓨터 위에선 자바 빌드 파일이 모두 실행 가능한 것처럼, 도커엔진이 깔려있는 컴퓨터에선 도커 컨테이너를 실행시킬 수 있다.
앞서 설명했듯, 도커 컨테이너는 하나의 프로세스이다. 그런데 하나의 머신처럼 작용한다. 하나의 머신으로, 내부에 실행해 필요한 실행 환경과 어플리케이션 빌드 파일을 모두 포함하고, 그 내부에서 파일이 실행될 수 있다. VM을 사용하는 대신 더 깔끔하고 빠르게 동작할 수 있는 도커 컨테이너를 사용할 수 있다고 정도로 가볍게 이해할 수 있다.
실행 환경과 실행 파일을 모두 포함한 파일을 도커 이미지 파일, 그리고 실행되고 있는 이미지 파일을 "컨테이너"라고 한다. 도커를 사용하지 않는다면 우리의 자바 어플리케이션을 서버 컴퓨터에서 구동시키기 위해 어플리케이션 코드에 맞는 OS를 설치하고, 맞는 버전의 JRE를 설치하고, 따료로필요한 bin 혹은 lib 파일이 있다면 구동되는 서버 컴퓨터에서 해당 파일들을 모조리 다시 다운받아야 할 것이다. 대신 우리는 패키징 결과 jar파일을 실행하기위한 기타 환경까지 모조리 포함한 도커 이미지 파일을 빌드한 후, 서버로 옮겨서 해당 이미지 파일을 실행시켜 컨테이너로 만들 것이다.
서버 컴퓨터에 어플리케이션 코드를 실행하기 위한 모든 환경을 구축하는 대신, 도커 엔진을 설치하고 컨테이너를 실행시킨다. 그리고 컨테이너에서 실행중인 프로그램과 서버 컴퓨터의 포트를 연결해 서버로 오는 요청을 도커 컨테이너로 전달한다. 간단하지 않나?!
도커 이미지를 빌드하기 위해선 Dockerfile이라는 파일을 프로젝트 루트 디렉토리에 작성하면 된다. 나의 경우, 자바 버전으로 17을 사용하고 있었고, 서버에서 구동될 컨테이너에선 "server"프로파일을 사용하고 싶었다.(스프링 프로파일에 대해 모른다면...묵념)
FROM openjdk:17-jdk-alpine
ENV USE_PROFILE=server
COPY build/libs/*.jar app.jar
ENTRYPOINT ["java",\
"-Dspring.profiles.active=${USE_PROFILE}",\
"-jar",\
"/app.jar"]간단하게 작성된 `Dockerfile`은 위와 같다.
- FROM으로 java 실행에 필요한 jdk 이미지를 다운받는다. jdk-alpine의 경우, jdk의 정말 최소한의 리소스만 가져온 가벼운 jdk 이미지라고 이해하자.
- ENV를 통해 도커 이미지에서 사용할 환경변수를 설정했고, COPY를 통해 build/libs 디렉토리 아래에 있는 jar 패키지 파일을 app.jar이라는 이름으로 루트 디렉토리로 불러왔다.
- ENTRYPOINT는 실제로 이미지를 빌드할 때 실행될 명령어이다. "java -jar"를 통해 빌드된 jar 파일을 실행할 것임을 알렸고, "-D"를 통해 profile을 전달했다. 그리고 실제로 실행할 copy된 /app.jar까지 작성해줬다.
그리고 Dockerfile이 있는 디렉토리에서 아래 명령어를 입력해 "myapp"이라는 이름을 가진 도커 이미지를 생성한다.
$ docker build . -t myapp:[tag]중요한 점이, 만약 나처럼 m2 맥을 사용하고 있다면 끝에 `--platform linux/amd64`를 붙여야 한다는 점.... arm 기반 프로세서를 사용하는 경우 스프링 이미지를 빌드하기 위한 linux이미지와 호환되지 않기 때문이다..
이제 이 이미지를 도커 허브에 업로드(=push)할 것이다. 그리고 서버 컴퓨터에서 해당 이미지를 다운(pull)받아 run 명령어를 통해 컨테이너를 실행할 것이다. 일련의 과정을 그림으로 살펴보면 아래와 같다.
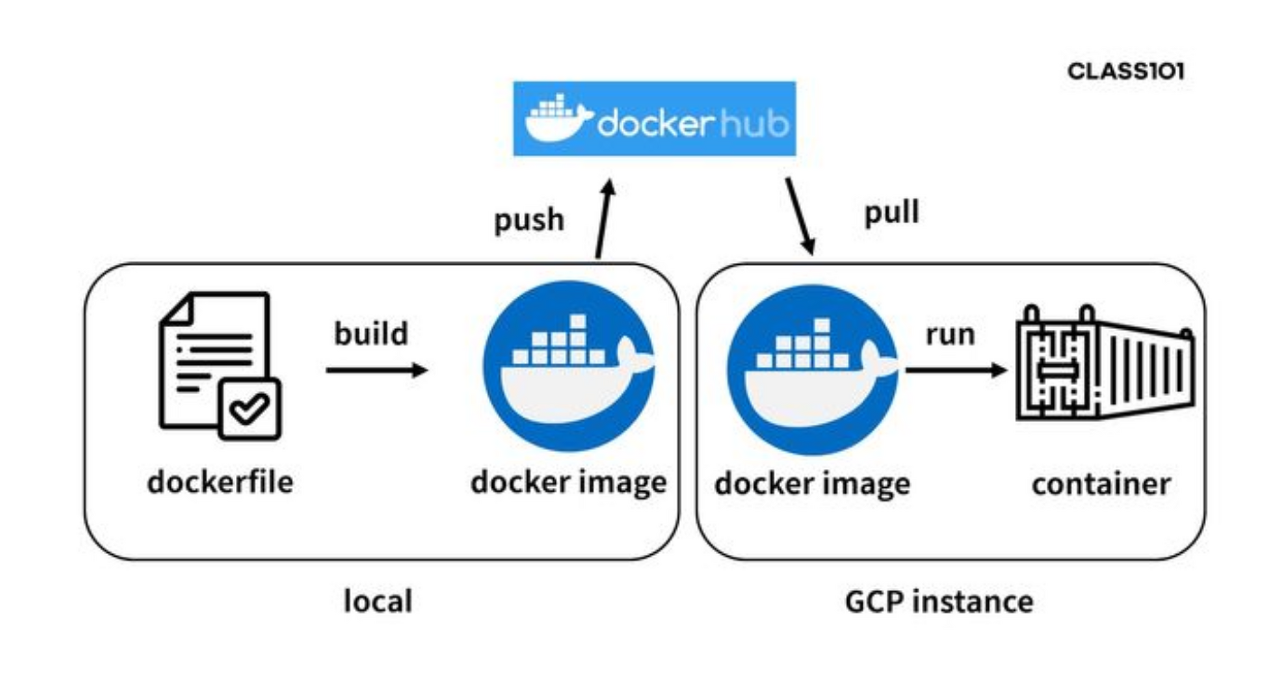
이제 도커 엔진이 설치된 서버 컴퓨터에서 이미지를 pull받은 뒤, 아래 명령어로 이미지를 컨테이너화하여 실행할 수 있다.
$ docker run -p 80:8080 myapp
# Jenkins가 하는 일
간단한 어플리케이션 실행 환경을 제공하는 도커를 사용한다고 해도, 여전히 개발자가 직접 이미지를 빌드하고, push하고, 서버 컴퓨터에서 pull하고, run해야하는 번거로움이 여전히 존재한다. 우리는 젠킨스라는 솔루션을 이용해서 해당 과정을 전~부 젠킨스에 맡긴다.
젠킨스는 개발된 소스코드를 빌드하여 패키지 파일로 만들고, 해당 파일을 도커 이미지로 빌드하고, 도커허브에 push한다. 그리고 ssh로 서버 컴퓨터에 접속해 이미지를 pull받고, 서버 컴퓨터에서 해당 이미지를 컨테이너화하여 실행시키는 일련의 과정을 전부한다. 여기서 개발자가 할 것은 새로 작성한 소스코드를 github에 push하는 것밖에 없다.
해당 과정을 이미지화해보면 다음과 같다.
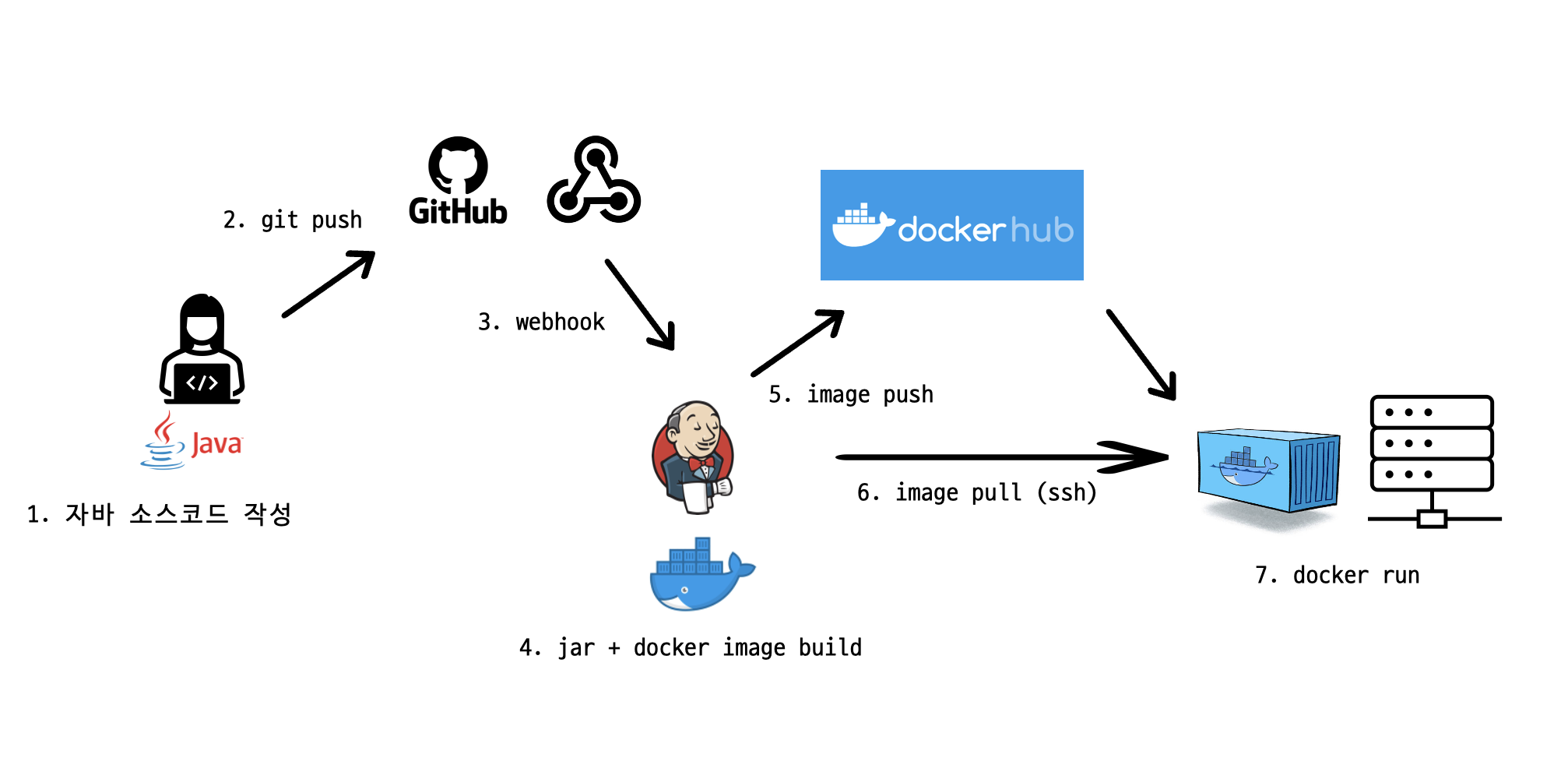
이러한 자동화 파이프라인을 구축하기 위해선 github webhook 설정, 이전에 우리가 직접 했던 도커 이미지 파일 빌드, 도커허브 push/pull, 이미지 실행 커맨드를 전부 젠킨스에 입력해줘야한다. 더해서 젠킨스가 서버 컴퓨터에 SSH로 접속하기 위한 비대칭 키 역시 설정해줘야 한다.(젠킨스에서 rsa 키를 만들고, 공개 키를 각 배포 서버에 등록해야함)
앞서 설명했듯.. 지금 목표는 이런 자세한 방법보단 배포 자동화가 무엇이며, 젠킨스가 여기서 어떤 역할을 할 수 있는지 알아보는 것이 중점이므로 가이드라인을 해줄 훌륭한 블로그 글을 링크로 첨부한다!
# SSH 통신에 대한 간단한 설명
글을 이만 줄이려고 했으나, SSH는 꽤나 중요한 토픽이기 때문에 간단히 설명하겠다. 우리는 서버 컴퓨터에 원격으로 접속해서 도커 이미지를 pull받고 run할 필요가 있다. 서버와 통신 포트를 열어서 네트워크로 서버가 실행할 명령어를 전송하는데 예전엔 23번 포트를 이용하는 telnet이라는 프로토콜을 이용했다.
telnet은 간편했다. 아무런 설정을 할 필요도 없이 그냥 23번포트로 띡 접속해서 명령어만 풍풍 날리면 됐기 때문이다. 하지만, 평문 통신이라는 치명적인 약점을 가지고 있었다. 서버에서 프로그램을 실행시키기 위해 입력하는 커맨드엔 보안에 취약한 정보가 있을 확률이 높다. 암호화 없이 평문으로 전송된 패킷은 중간에 탈취당했을 때 공격자에게 그대로 노출될 것이고, 이는 정보 보안의 측면에서 상당히 좋지 않은 결과를 불러일으킬 것이다.
때문에 비대칭키 암호화 방식을 이용하는 SSH 프로토콜이 필요하게 되었다. SSH는 22번 포트를 이용한다. 비대칭키 암호화 방식이란 "암호화(encryption)와 복호화(decryption)에 이용하는 키가 다른 프로토콜이다. public key(공개 키) - private key(비밀 키, 혹은 개인 키)쌍이 존재하며, 공개 키로 암호화한 것은 개인 키로만 복호화할 수 있고 개인키로 암호화한 것은 공개 키로만 복호화할 수 있다. 젠킨스 서버에서 키 쌍을 만들고 배포 서버에 공개키를 공개한다. 그리고 자신의 비밀 키로 ssh를 통해 보낼 커맨드를 암호화한 뒤 배포 서버에 보내면, 배포 서버는 이전에 받은 젠킨스의 공개 키로 해당 커맨드를 복호화하여 읽는다.
평문 HTTP 통신을 암호화 통신으로 보완한 HTTPS 역시 비슷한 방식으로(하지만 한 단계 더 복잡함) 통신한다. HTTPS에 관한건 66일 챌린지를 할 때 작성한 블로그 글의 2번 항목을 다시 공부하자!