
선요약 : 레시피의 태그, 제목, 항목 등의 검색에 JPQL을 사용하다 쿼리 구성이 더 간편하고 검색 속도가 빠른 엘라스틱 서치를 사용했습니다. 인덱싱 작업을 메세지 큐에 넘겨 트랜잭션으로 묶일 필요가 없는 작업들을 메세징 처리했습니다. (하단 서버 구조 참고 - 원래 4번은 worker 모듈을 따뤄 둬야 합니다!)
# 상황 : 레시피 검색!
Recipetory는 레시피가 존재하는 레시피 공유 사이트이다. 레시피를 업로드하고 조회하는 기능 이외에 메인 기능이라고 한다면 "레시피 검색 기능"이다.
보통 "제목"과 "특정 태그"를 포함하는 컨텐츠에 대한 검색 기능을 제공하는 서비스를 생각해보면,
- 특정 제목과 항목을 가진 컨텐츠를 검색할 수 있다.
- 특정 태그(들)를 포함한 컨텐츠를 검색할 수 있다.
.. 정도의 기능을 구현해야할 것 같다. 그래서 각 기능을 수행하는 컨트롤러 메소드를 `RecipeSearchController`에 추가했다. 잠깐 domain-specific한 정책을 짚고 넘어가자면 레시피 항목에는 각각의 enum value가 존재하는 cookingTime / difficulty / serving으로 이루어져있다. (domain 코드 참고)
@Controller
@RequiredArgsConstructor
@Slf4j
public class RecipeSearchController {
private final RecipeSearchService recipeSearchService;
/**
* title과 recipeInfo 조건에 맞는 레시피를 검색한다.
*/
@GetMapping("/recipes")
public ResponseEntity<RecipeListDto> searchRecipe(
@RequestParam(name = "q", defaultValue = "") String title,
@RequestParam(name = "t", defaultValue = "UNDEFINED") String cookingTime,
@RequestParam(name = "d", defaultValue = "UNDEFINED") String difficulty,
@RequestParam(name = "s", defaultValue = "UNDEFINED") String serving
) {
RecipeListDto found = recipeSearchService.findRecipeByRecipeInfo(
title.trim(), cookingTime, difficulty, serving);
return ResponseEntity.ok(found);
}
/**
* query parameter로 들어온 tag를 전부 포함하는 레시피를 검색한다.
* @param tags
* @return
*/
@GetMapping("/recipes/tags")
public ResponseEntity<RecipeListDto> searchRecipeByTags(
@RequestParam(name = "t", defaultValue = "") List<String> tags
) {
RecipeListDto found = recipeSearchService.findByTags(tags);
return ResponseEntity.ok(found);
}
}주석에 적힌대로 searchRecipe()는 제목과 레시피 조건으로, searchRecipeByTags()는 특정 태그를 "전부" 포함하는 레시피를 검색하는 api 엔드포인트를 제공한다. 이제 해당 기능을 구현하는 실제 search method를 구현해야한다.
# JPQL 작성해보기
현재 레시피가 저장된 DB는 MySQL이다. 각각의 기능(제목 및 항목으로 검색, 태그를 전부 포함하는 레시피 검색)을 달성하기 위해선 쿼리를 작성해야 한다.
항목과 일치 여부에 대한 검색은 "=" 연산자로, 제목을 포함하는 레시피에 대한 쿼리는 Like 키워드로 쿼리를 작성할 수 있다고 해도, JPA를 사용하는 상황에서 "모든 태그를 포함하는 레시피를 검색하기"란 꽤나 까다롭다.
현재 DB 접근을 위해 Spring Data JPA를 사용하고 있어, JPQL을 작성했다. JPQL이란? Java Persistence Query Language로, JPA의 엔티티 기반 쿼리를 작성할 수 있게 해준다. Jpa Repository 메소드에 @Query 어노테이션 속성으로 쿼리를 직접 작성할 수 있다. 다음은 JpaRepository를 extends한 repository interface 코드의 일부이다.
@Query("SELECT DISTINCT r FROM Recipe r " +
"JOIN FETCH r.author " +
"WHERE r.title LIKE %:title% " +
"AND (r.recipeInfo.cookingTime = :cookingTime OR :cookingTime = 'UNDEFINED')" +
"AND (r.recipeInfo.difficulty = :difficulty OR :difficulty = 'UNDEFINED')" +
"AND (r.recipeInfo.serving = :serving OR :serving = 'UNDEFINED')")
List<Recipe> findByRecipeInfo(
@Param("title") String title,
@Param("cookingTime") CookingTime cookingTime,
@Param("difficulty") Difficulty difficulty,
@Param("serving") Serving serving);
/**
* tagNames의 tagName을 전부 포함하는 레시피들을 검색한다.
* @param tagNames
* @param tagSize
* @return
*/
@Query("SELECT DISTINCT r FROM Recipe r " +
"JOIN FETCH r.author WHERE " +
":tagSize > 0 AND :tagSize = " +
"(SELECT COUNT(t) FROM Tag t WHERE " +
"t.recipe = r AND t.tagName IN :tagNames)")
List<Recipe> findByTags(
@Param("tagNames") List<TagName> tagNames,
@Param("tagSize") int tagSize,
Pageable pageable);첫번째가 제목 및 레시피 항목으로 레시피를 검색하는 쿼리 메소드, 두번째가 태그를 전부 포함하는 레시피를 검색하는 쿼리 메소드이다.
검색 항목이 "UNDEFINED"인 경우 검색 조건에서 제외한다는 것만 알아두면 그나마 첫 번째 쿼리는 이해할 수 있다.
그러나 findByTags()의 경우, 쿼리가 조금 복잡하다. 일단 파라미터로써 검색하고자하는 tagNames 리스트와 tagNames의 길이인 tagSize를 받는다. 그 뒤 태그를 기준으로 검색하는데, 레시피에 포함된 태그 중 검색하고자 하는 태그와 일치하는 태그수가 tagSize와 같은 레시피를 찾게 되는 것이다. 이렇게 되면 tagNames에 있는 태그를 전부 포함하는 레시피를 검색할 수 있다. ... 이해할 수 있도록 말로 만들기도 힘든데, 읽으면 더 이해가 안갈 것 같다.
# 초간단 Elastic Search
ES 역시 66일 챌린지를 했을 적에 작성했던 블로그 글이 있으므로 해당 글을 참고하면 되는데, 그래도 한 번 더 간단하게 복기해보자. 엘라스틱 서치는 NoSQL로, "inverted index"기반으로 데이터를 저장하고 샤딩을 통한 빠른 검색에 특화된 데이터 엔진이라고 설명할 수 있다.
데이터가 저장될 때, 단어 단위로 쪼개져 해당 단어가 존재하는 데이터로 바로 이동할 수 있도록 인덱싱을 하는 것이다. 데이터를 저장할 때 인덱스 필드에 해당하는 값에 따라 정렬 공간을 만들어놓는 SQL의 인덱스와는 차이가 있다. 또한 ES는 데이터 샤딩을 통해 전체 DB 데이터를 각 샤드에 나눠서 보관하고, 여러 개의 워커 노드들이 각 샤드에서 데이터를 병렬적으로 검색하여 빠른 검색 속도를 보인다.
데이터의 단어를 쪼개고 구문을 분석하는 일, 즉 인덱싱은 tokenizing ~ 동의어 처리까지 꽤 시간이 걸려서(그래봤자 1-2초지만) 완전한 실시간성을 보장하긴 힘들다. 때문에 insert가 자주 일어나는 데이터나, 방금 insert된 데이터의 실시간성이 중요할 때는 권장되지 않는다. 그러나 현재 프로젝트 "레시피 공유 사이트"의 경우, 1. 레시피를 작성하는 것보단 레시피를 조회하는 상황이 압도적으로 많을 것이고 2. 데이터 자체에 대한 실시간성은 그렇게 중요하지 않으므로 ES를 도입할 것을 고민 끝에 결정하게 되었다.
# 프로젝트 아키텍처 : indexing 비동기 처리
프로젝트는 기존의 JPA entity를 유지한 채, 검색 전용 DB로써 ES가 추가된 형태를 띈다. 때문에 기존 @Entity 코드에 더해 @Document 클래스가 추가로 필요하다. ES를 도입하고 코드 설정을 하는 상세한 방법에 대해 다루고자 하는 포스트가 아니므로, 해당 과정은 생략하겠다.
앞서 언급한 ES의 주의할 점에 대해, 인덱싱은 시간이 오래 걸리는 작업이기 때문에 인덱싱 작업이 전부 끝난 뒤에 유저가 응답을 받게 된다면 이상적이지 않은 사용자 경험이 될 것이다. (사실 POST는 자주 일어나는 작업이 아니라 그렇게까지 치명적이진 않겠지만 공부한다는 마음가짐으로). 따라서 ES 인덱싱 처리하는 과정을 메세지 큐로 넘기기로 했다. 엔티티 객체가 생성된 뒤, 생성된 엔티티 객체를 바탕으로 document를 생성할 수 있도록 이벤트 기반 메세지 처리를 할 것이다. 그림으로 해당 과정을 그려보겠다.
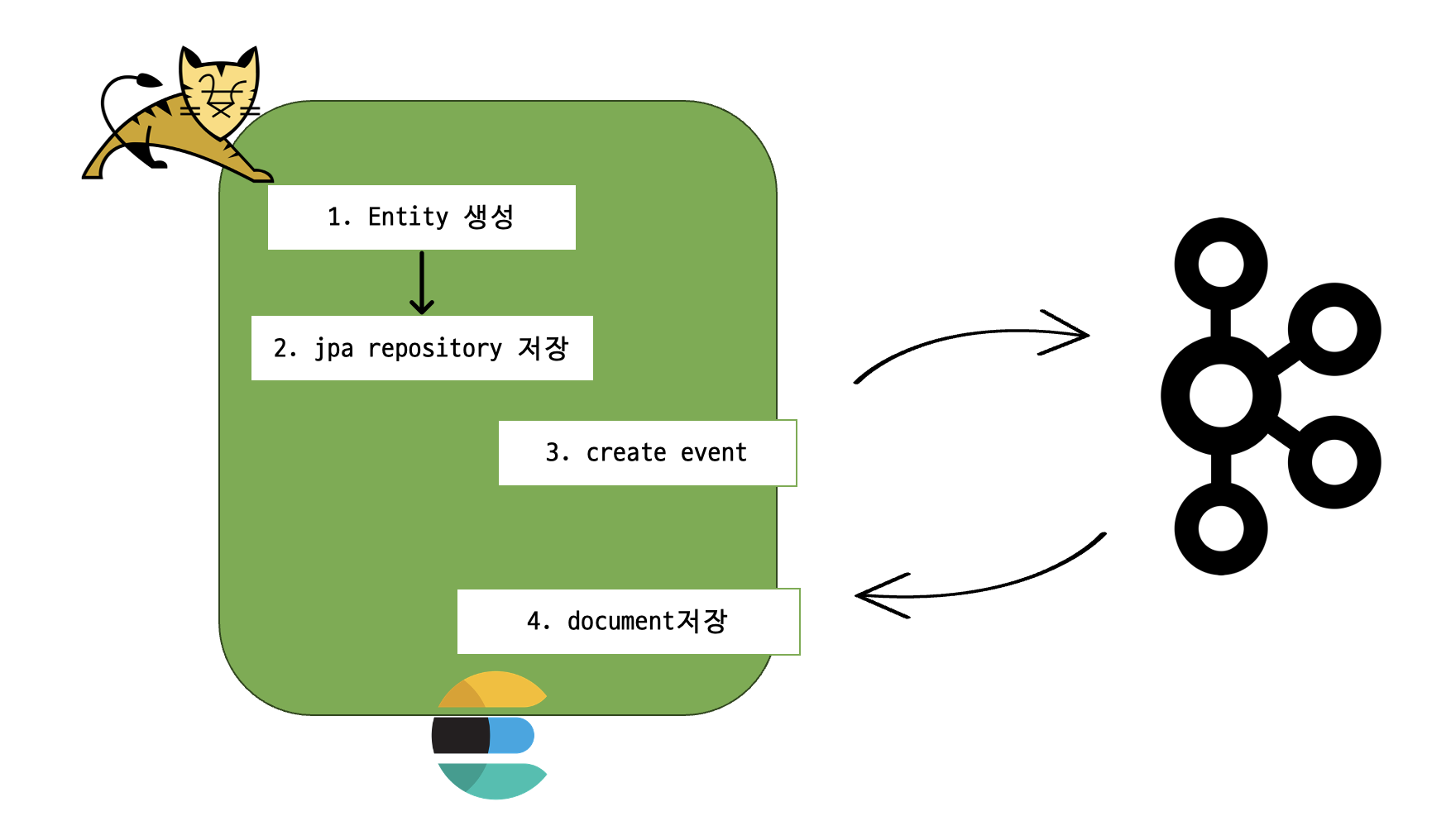
- tomcat WAS에서 Recipe entity를 생성한다.
- JPA Repository에 저장한다.(MySQL 테이블에 저장됨)
- ApplicationEventPublisher를 통해 CreateRecipeEvent가 발행된다. 이벤트 리스너가 document 정보를 카프카 메세지 큐에 전송한다.
- 메세지를 받은 카프카 리스너가 document를 es index에 저장한다.
ApplicationEventPublisher를 통해 CreateRecipe 이벤트를 발행하면, 아래 이벤트 리스너가 실행된다.
@Service
@Slf4j
@RequiredArgsConstructor
public class DocumentListener {
private final KafkaDocumentMessageSender documentMessageSender;
/**
* 생성된 recipe Entity를 ES에 반영하기 위해 kafka message를 보낸다.
*/
@TransactionalEventListener
@Async
public void createRecipeDocument(CreateRecipeEvent createRecipeEvent) {
RecipeDocument document = RecipeDocument.fromEntity(
createRecipeEvent.getRecipe());
documentMessageSender.sendRecipeDocument(document);
}
}`RecipeDocument`는 ES 인덱스에 저장될 document 그 자체이다. fromEntity()를 static 메소드로 가지고있어 엔티티 정보로부터 document를 생성할 수 있다. 이벤트 리스너가 카프카 메세지를 보내면, 아래와 같은 카프카 리스너가 해당 메세지를 consume한다.
@Service
@Slf4j
@RequiredArgsConstructor
public class KafkaDocumentListener {
private final RecipeDocumentRepository recipeDocumentRepository;
/**
* Kafka message로 도착한 RecipeDocument를 indexing한다.
*/
@KafkaListener(topics = KafkaTopic.NEW_RECIPE,
containerFactory = "recipeDocumentKafkaListenerContainerFactory",
groupId = "${spring.kafka.group-id}")
public void documentListener(RecipeDocument document) {
log.info("recipe document id {} 저장", document.getId());
recipeDocumentRepository.save(document);
}
}RecipeDocumentRepository는 Spring data ElasticSearch에서 제공하는 ElasticSearchRepository를 extends하는 Repository 인터페이스이다. 기본적인 save, delete 연산을 위해 사용했다.
이로써 document 저장에 메세지 큐가 포함되어 아키텍처는 약간 복잡해졌지만, post 과정에서 병목이 될 수도 있는 ES 인덱싱을 비동기적으로 처리할 수 있게 되었다. 나중에 MSA로 프로젝트가 확장되면 인덱싱을 처리하는 모듈만 따로 분리할 수도 있을 것이다.
ES 구성을 완료했으므로 다음은 실제로 엘라스틱 서치를 이용한 쿼리 구성을 어떻게 했는지 포스팅해보도록 하겠다.