선요약 : 호출이 많이 일어날 것으로 예상되는 메인 페이지의 "추천 컨텐츠"에 캐시를 적용하여 전반적 성능을 1.5배 향상시켰습니다. 또한 컨텐츠 추천에 사용되는 로그 연산을 위해 elastic search script를 사용하였습니다.
# 컨텐츠 추천을 위한 로직
프로젝트에서 사용하는 메인 컨텐츠는 조리법이 설명된 "레시피"이다. 사용자가 서비스의 index 페이지에 접속했을 때, 추천하는 레시피를 10개 정도 뽑아 홈페이지에서 볼 수 있도록 구성하고 싶었다. ML 솔루션을 도입해 사용자 개개인에 맞는 추천 레시피를 설정할 수도 있겠고, 최근 데이터에 weight을 주어 최근에 많이 조회된 컨텐츠를 추천할 수도 있겠다.
그러나 현재 단계에선 간단하게, 레시피의 조회수와 평점을 기준으로 높은 점수를 가진 컨텐츠를 추천하기로 결정했다. 점수는 다음과 같이 레시피의 두 컬럼을 간단히 더하는 것으로 구성할 수 있겠다.
score = 조회수(viewCount) + 평점(ratings)
평점은 1.0~5.0의 값을, 조회수는 말 그대로 viewCount만큼의 자연수를 값으로 갖는다. 그러나 단순히 위와 같이 구성한다면, 두 항목의 단위가 달라 문제가 발생한다.
- 사용자들이 모두 만족해서 평점이 4.99를 기록했지만, 조회수가 100 남짓한 이제 막 생겨난 레시피
- 어쩌다 광고에 걸려 조회수가 십만 단위로 올라갔지만, 맛이 좋지 않아 평점이 1점대인 레시피
본래의 계산 방식대로라면, 상식적으로 1번이 더 추천에 적합한 컨텐츠임에도 2번의 점수를 절대 넘어설 수 없다. 평점은 높아봤자 5점이지만 조회수는 한계 없이 늘어날 수 있기 때문이다. 따라서 두 항목의 단위를 적절하게 맞춰줘야 한다.
서비스가 어느정도 사용되고 사용자 규모가 보이면 적절히 두 항목을 조절하는 함수를 사용할 수 있겠지만, 개발 단계인 지금은 log함수를 사용하기로 결정했다. log는 자릿수 단위로 항목 점수를 계산해주기 때문에 조회수와 평점간 단위 거리를 좁혀줄 수 있을 것이다.
score = 조회수(viewCount) + log(평점)
컨텐츠 추천에 사용되는 점수는 document의 각 항목을 이용한 값이다. 그리고 해당 값은 사용자들이 컨텐츠를 조회하거나 평점을 매길 때마다 변한다. 따라서 score 자체를 또다른 필드로 둔다면 각 항목의 값이 변할 때마다 score도 업데이트되어야 한다. 그것보단 elastic search에서 제공하는 script를 사용하는 것이 적절할 것 같다.
# ES Script
전술한 방법으로 score를 계산하고, 해당 값에 따라 document들을 내림차순으로 정렬한 뒤, 원하는 개수만큼 결과값을 가져오는 쿼리를 작성해야한다. 이 과정을 편하게 해주는 ScriptSort라는 es 모듈이 존재한다.
엘라스틱 서치에선 doc['<fieldname>'].value로 document의 필드 값에 접근하는 것이 가능하다. 해당 방법으로 스크립트를 직접 작성하여 쿼리를 구성할 것이다. spring data elastic search의 현재기준 최신 버전인 5.x, ES의 최신 버전인 8.x에선 기존의 HighLevelClient와 쿼리를 작성하는 방식이 달랐다.
- 조회수 + log(평점)을 해당 방법으로 계산하는 문자열 스크립트를 작성한다.
- ScriptSort 쿼리를 작성한다. 1번에 작성한 문자열 스크립트를 추가한다.
- 내림차순 정렬을 위한 Desc옵션, 그리고 정렬에 사용되는 값이 숫자임을 나타내는 Number 옵션을 추가한다.
- 현재 정렬에 사용되는 필드는 recipeStatistics라는 항목 밑에 있는 nested 필드이다. nested()옵션에 이 사실을 명시한다.
그 뒤 기존에 ElasticSearchClient를 이용한 쿼리 방식으로 결과를 받으면 된다. 백문이 불여일코, 방금 설명한 쿼리 메소드는 아래와 같다.
/**
* view count, ratings를 기준으로 레시피를 내림차순으로 정렬하여
* 인자로 전달된 갯수만큼의 레시피를 반환한다.
*/
public List<RecipeDocument> getTopRecipe(int number) {
try {
// 평점(ratings), 조회수(viewCount)를 이용해 추천에 사용될 점수를 계산하는 script
String script = "doc['recipeStatistics.ratings'].value + " +
"Math.log(1 + doc['recipeStatistics.viewCount'].value);";
// nested field의 값을 이용한 결과를 내림차순으로 정렬하는 쿼리 source
ScriptSort source = SortOptionsBuilders.script()
.script(Script.of(sc -> sc.inline(InlineScript.of(i -> i.source(script)))))
.type(ScriptSortType.Number)
.order(SortOrder.Desc)
.nested(NestedSortValue.of(sv -> sv.path("recipeStatistics"))).build();
SearchResponse<RecipeDocument> response = esClient.search(
s -> s.index("recipe").size(number).sort(so -> so.script(source)), RecipeDocument.class);
return response.hits().hits().stream().map(Hit::source).toList();
} catch (IOException e) {
throw new EsClientException("recipe");
}
}
# 캐시 사용 고려
인덱스는 홈페이지이다. 홈페이지는 일반적으로 서비스에서 가장 많은 트래픽이 몰리는 구간이다. 만약 1000명의 동시 사용자가 있다면 앞서 구성한 스크립트 쿼리가 DB에 1000번 나가게 되는 것이다. 컨텐츠 자체에 대한 추가나 수정은 많이 없을 것으로 예상되기 때문에, 추천 컨텐츠 역시 대부분의 사용자들에게 같은 결과로 응답될 것이다.
앞선 getTopRecipe()는 다음과 같은 특징이 있다.
- 매우 많이 호출될 것으로 예상된다.
- 데이터의 신선도가 크게 중요하지 않다.(실시간성이 보장되지 않아도 상관없다)
- 결과가 자주 수정되지 않는다.
캐시를 도입하기 아주 적절한 상황이다.
캐시는 간단히 말하면 "임시 저장소"이다. 원본 데이터를 검색하기 위해 모든 요청에 대해 DB 쿼리를 날리는 대신, 캐시 저장소에 한 번 구성된 응답 데이터를 저장해놓고 같은 요청이 들어오면 캐시 저장소에 저장된 데이터를 반환하는 것이다. 캐시 데이터가 존재하는동안 DB서버 데이터가 업데이트된다면 데이터 불일치가 발생할 가능성이 있지만, 캐시 만료시간 안에서 허용될 정도라면 캐시를 사용하는 것이 이점이 크다.
간단하게 읽기와 쓰기에 대한 캐시 전략을 살펴보면 다음과 같다.
- 읽기(Read) 전략
- Look Aside : 캐시 서버를 먼저 확인한 후, 캐시 미스가 날 때만 원본 데이터를 요청하는 방식.
- Look Through : 캐시 서버에서만 데이터를 가져오는 방식.
- 쓰기(Write) 전략
- Write Back(Behind) : 캐시 서버에 데이터를 썼다가, 특정 시점에 배치 작업으로 DB에 업데이트 하는 방식.
- Write Through : DB와 캐시 서버 모두에 데이터를 쓰는 방식.
- Write Around : DB에만 데이터를 쓰는 방식. Look Aside와 함께 가장 많이 사용된다.
# Redis : key-value 구조의 인메모리 저장소
캐시는 데이터의 실시간성을 어느정도 포기하는 대신 빠른 성능을 택했다. 서버 자체도 이에 대한 니즈를 맞춰야 하기 때문에, 캐시 데이터를 디스크에 보관하지 않고 빠르게 접근 가능한 메모리에 두고 key값을 통한 요청에 바로 응답할 수 있도록 구성되어야 한다.
캐시 서버로 많이 사용되는 솔루션으로 Memcached와 Redis가 존재한다. Memcached의 경우 문자열로 된 간단한 key-value 구조를 통해 가볍고 빠른 캐시 서버 구성이 가능하다. 그러나 캐시 데이터에 대한 영속성을 지원하지 않고, 문자열 이외의 복잡한 데이터 구조는 지원하지 않는 점이 걸렸다. 따라서 List, Map 등 더 다양한 자료구조를 지원하며 캐시 데이터 업데이트 및 만료시간을 더 정교하게 지정할 수 있는 Redis를 사용하기로 결정했다.
Redis 도입 자체에 대한 것 역시 간단한 검색으로 찾을 수 있는 훌륭한 블로그 글로 대신하고, (여담인데 프로젝트에서 대부분의 솔루션 도입은 [종속성 추가 - yml 및 config 컴포넌트 설정 작성 - 사용하고자 하는 부분에 솔루션 코드 추가]의 형태를 띄는 것 같다) 실제로 캐시 데이터로 저장될 "추천 컨텐츠"를 반환하는 서비스 메소드에 @Cacheable 어노테이션을 붙여보았다.
/**
* index에 제공할 추천 레시피를 반환한다.
*/
@Cacheable(value = "getFeaturedRecipes", cacheManager = "redisCacheManager")
@Transactional(readOnly = true)
public RecipeListDto getFeaturedRecipes() {
List<RecipeDocument> featured = recipeRepository.getFeatured();
return RecipeListDto.fromDocumentList(featured);
}value 옵션은 Redis 서버에서 사용되는 key값이다. 보통 key="#~~"옵션과 붙어 동적 키로 구성되어 함께 사용되는데, 현재 추천 레시피는 따로 추가 키가 필요하지 않으므로 value 옵션만 설정했다. cacheManager는 아래 코드와 같이 구성했는데, 간단히 Serializer/Deserializer를 정의하고, 캐시 서버의 IP 주소와 레디스의 포트 번호를 지정한 connection factory를 붙여주었다.
@Configuration
@RequiredArgsConstructor
public class CacheConfiguration {
private final RedisConnectionFactory redisConnectionFactory;
private static final long CACHE_TTL = 2L;
@Bean
public CacheManager redisCacheManager() {
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
.serializeKeysWith(RedisSerializationContext
.fromSerializer(new StringRedisSerializer()).getKeySerializationPair())
.serializeValuesWith(RedisSerializationContext
.fromSerializer(new GenericJackson2JsonRedisSerializer()).getValueSerializationPair())
.entryTtl(Duration.ofHours(CACHE_TTL));
RedisCacheManager cacheManager = RedisCacheManager.RedisCacheManagerBuilder
.fromConnectionFactory(redisConnectionFactory)
.cacheDefaults(redisCacheConfiguration).build();
return cacheManager;
}
}TTL(Time To Live)는 2시간으로 설정했는데, 특정한 이유는 없고 그냥 인간은 2시간마다 배가 고파질 것이라고 막연히 생각했기 때문이다(..)
# 성능 개선
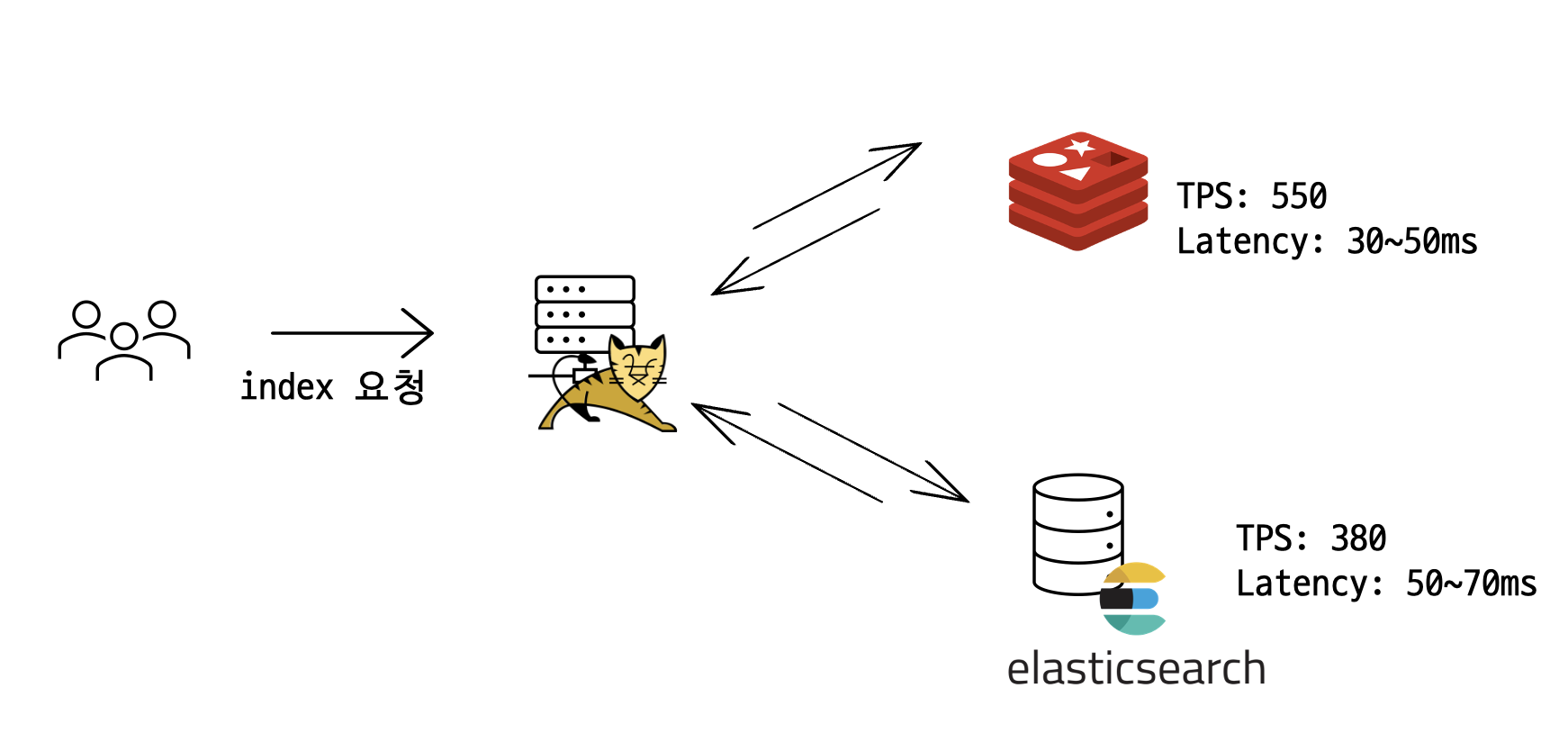
GCP의 e2.micro를 사용한 단일 서버 기준으로, 캐시 서버 없이 DB에 직접 쿼리 응답을 받을 경우 index 페이지에서 받을 수 있는 평균 TPS는 380, latency는 50~70ms였다. (60만개 document 기준)
es와 같은 스펙(e2 small = 2vCPU, 2GB RAM)의 레디스 서버를 하나 둔 결과 TPS와 latency 는 각각 550, 30~50ms로 약간의 개선이 이뤄졌다.