
프로젝트에 메세지 큐로써 카프카를 사용했지만, 카프카가 무엇이며 왜 사용했으며, 그 구조가 어떻게 되어있는지는 개념적으로 설명하지 않은 것 같아 간단하게 정리하겠습니다.
1. 카프카 : 메세징 시스템
프로젝트 기능을 구현하기 위해 시스템 모듈간 메세지나 데이터를 교환해야할 필요가 있습니다. 서비스 모듈에서 처리된 데이터를 DB 모듈로 옮기거나, 알림 모듈에서 발생한 데이터를 로깅 모듈로 옮기는 등 필요한 상황은 매우 많습니다. 이를 구현하기 위해 생각해 볼 수 있는 방법은 데이터 교환이 필요한 모듈마다 버스를 구성해서 point to point 통신을 하는 것인데, 개략적인 모습은 아래와 같습니다.
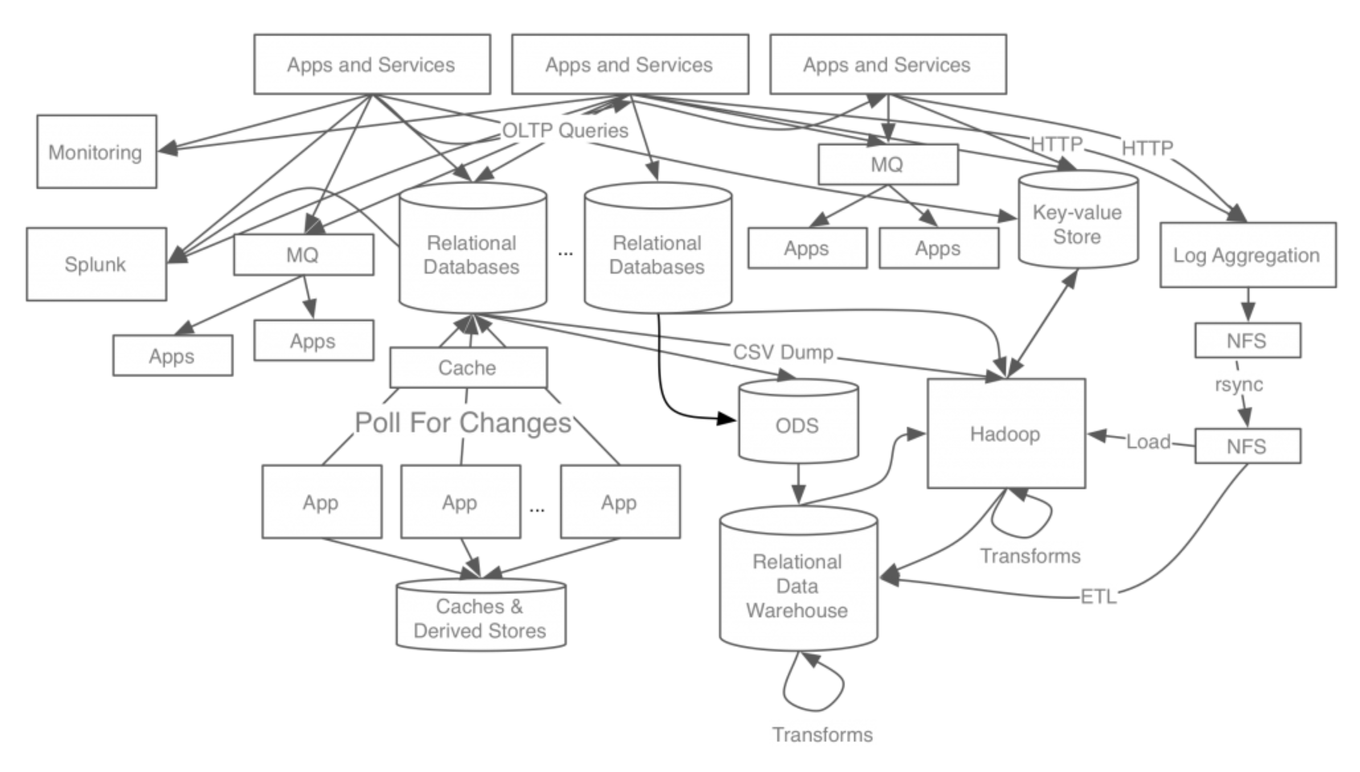
별로 이상적이지 않죠? 아키텍처의 복잡도가 필요 이상으로 올라가고, 시스템의 각 모듈이 강하게 결합되어 있어 모듈을 수정하거나 추가/삭제하는 등의 구조 개선이 상당히 어려워집니다. 5개의 모듈로 이뤄진 프로젝트의 각 모듈을 연결하기 위해선 10개의 버스(Bus)가 필요하고, 1개의 모듈이 추가되면 그 모듈만을 위해 5개의 연결 버스가 추가로 필요하게 됩니다.
이렇게 복잡한 그물망을 구성하는 대신, 아키텍처 중앙에 데이터 교환을 전문적으로 처리하는 메세징 시스템이 있으면 훨씬 좋을 것 같습니다. 전송 데이터를 받아서, 해당 데이터가 필요한 모듈들에게 한번에 뿌려줄 수 있다면 아키텍처가 훨씬 간단해질테고 메세지 처리 자체도 조금 더 정교하게 할 수 있을 것입니다. 메세지를 보관했다가 한 번에 처리를 하게 한다거나, 메세지에 영속성을 부여하는 옵션을 추가할 수도 있을테고요. 이 필요에 의해 생겨난 것이 카프카입니다. 분산 모듈 환경에서 중앙 집중식 메세징 아키텍처를 달성한다고 하여 "분산 메세징 시스템"이라는 짧은 설명이 붙었습니다.
다음은 기존의 아키텍처 중앙에 메세지 처리를 담당하는 카프카를 도입했을 때 바뀐 모습입니다.
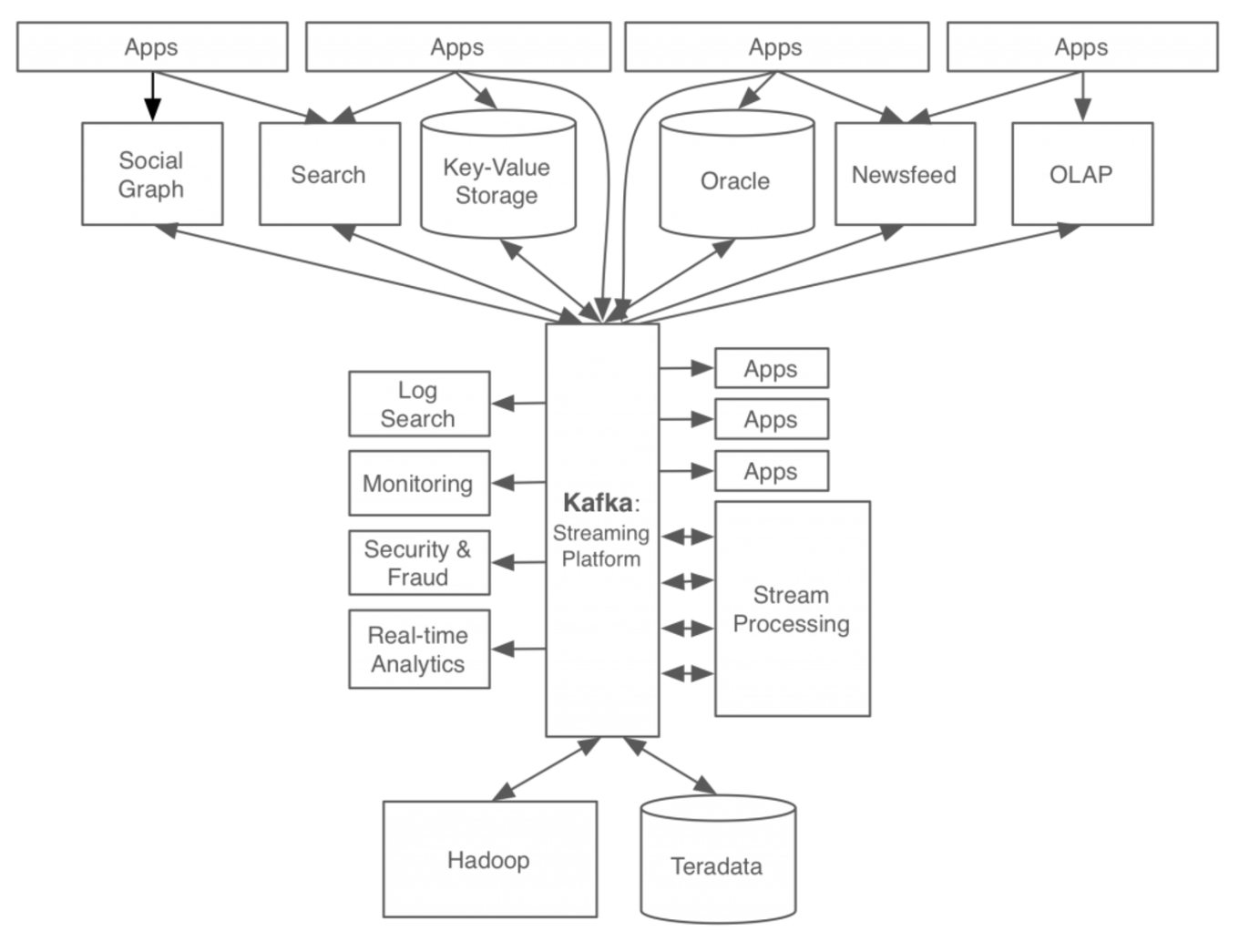
이전과 비교해 훨씬 간단한 아키텍처가 완성되었습니다.
모듈 A에서 모듈 B로 데이터를 전송해야할 일이 생긴다면, A는 카프카에게 메세지를 던지고, B는 카프카에게 해당 메세지를 받으면 됩니다. 이 상황에서 모듈 C 역시 데이터를 받아야 하는 요구사항이 추가된다면, A와 연결 버스를 추가하는 대신 간단히 C 역시 카프카로부터 데이터를 pull할 수 있도록 설정하면 되겠죠?
2. 카프카 아키텍처
카프카는 Publisher/Subscriber 구조로 되어있습니다. 한국어로 발생자, 구독자라고 이해하면 됩니다. 특별한 뜻은 없고 말 그대로 데이터 발행/구독을 뜻하는 pub/sub 구조입니다. 유튜브로 빗대어 설명해보면, 구독하는 유튜버가 유튜버에 동영상을 발행하면 구독자들은 유튜버에 들어가서 발행된 동영상을 시청하게 됩니다. 카프카 역시, Producer(= Publisher)가 카프카에 데이터를 발행하면 Consumer(= Subscriber)가 카프카의 데이터를 pull하여 사용하는 것입니다. 프로듀서 모듈과 컨슈머 모듈은 별개로 존재하며, 이 과정은 비동기적으로 이뤄집니다.
조금 더 내부로 들어가 살펴보기 전에, 카프카에서 사용하는 용어에 대해 설명하고 넘어가겠습니다.
- 프로듀서 (producer) : 카프카의 특정 토픽에 레코드를 추가하는 모듈입니다.
- 컨슈머 (consumer) : 카프카의 특정 토픽을 구독하고, 토픽의 파티션에 쌓인 레코드를 처리하는 모듈입니다. 기본적으로 파티션의 오프셋 순서대로 데이터를 처리하지만, 다른 파티션의 레코드 사이에선 순서가 보장되지 않습니다.
- 브로커 (broker) : 개별 카프카 서버를 의미합니다. 하나의 카프카 프로세스로, 여러 개의 토픽과 토픽 내부의 파티션을 갖습니다. Producer에게 받은 데이터(레코드)를 저장하고 Consumer에게 전달합니다.
- 카프카 클러스터 : 카프카 브로커들이 모여 카프카 모듈을 이룬 집합입니다. 카프카는 이렇게 여러 브로커들이 모인 클러스터로 구성되어, 브로커를 쉽게 추가하거나 삭제할 수 있고, 레코드를 복제(replica) 관리하여 클러스터의 일부에 장애가 발생하더라도 전체 서비스를 이어나갈 수 있습니다. 이를 두고 확장성과 내결함성이 높다고 말합니다.
- 레플리카 (replica) : 전술했듯 클러스터 일부의 장애가 발생하더라도 레코드 데이터를
- 토픽 (topic) : 카프카에서 관리하는 데이터(레코드)의 종류입니다. Producer는 카프카의 특정 토픽으로 데이터를 전달하고, Consumer 역시 카프카의 특정 토픽에 쌓인 데이터를 pull합니다.
- 파티션 (partition) : 하나의 토픽 안에 존재하는 구분 단위입니다. 카프카의 각 토픽은 하나 이상의 파티션으로 구성됩니다. 특정 토픽으로 전달된 데이터들은 여러개의 파티션으로 나뉘어 병렬 처리가 가능한데, 파티션이 여러개일 때 따로 키Key 설정이 없다면 RR 방식으로 레코드가 나뉘어 전송되지만, 같은 Key로 보내진 레코드는 같은 파티션으로 전송됩니다. 찾아보니 특정 파티션으로
- 레코드 (record) : 카프카에서 사용하는 데이터 단위입니다. Producer 모듈이 레코드를 카프카에 발행하고, Consumer 모듈이 레코드를 카프카에서 pull한다고 이해하면 충분합니다. Key, Value, TimeStamp, Offset id 등으로 구성됩니다.
- 오프셋 (offset) : 이해하기 쉽게 말하면, 파티션 내부에 존재하는 데이터 순서입니다. 카프카는 파티션 단위로 보면 큐Queue처럼 동작하기 때문에, 파티션 내부의 레코드들은 sequencial offset id를 갖고 Consumer에 의해 순서대로 처리됩니다. 오프셋은 다른 파티션 사이에선 공유되지 않으며, 앞서 설명한대로 다른 파티션의 레코드들은 병렬적으로 처리될 수 있습니다.
- 컨슈머 그룹 (Consumer Group) : 특정 토픽에 쌓인 레코드들을 처리하는 같은 모듈이 여러개 있을 수 있습니다. 웹 서버를 다중으로 구성하는 것처럼 말이죠. 같은 레코드를 병렬적으로 처리할 수 있도록 여러 개의 컨슈머 모듈들을 하나의 컨슈머 그룹으로 묶어 파티션으로 나뉜 토픽 레코드들을 병렬적으로 처리하도록 구성할 수 있습니다.
- 주키퍼 (zookeeper) : 리더 브로커를 선출하고 메타데이터를 관리하는 등 카프카 클러스터의 전반적인 조정을 담당하는 모듈입니다. 그러나 최신 버전의 카프카는 전술한 기능을 브로커 자체적으로 수행할 수 있어 주키퍼에 대한 의존성이 줄어들었습니다.
이제 방금 배운 용어들을 이용해 카프카 아키텍처를 설명해보겠습니다. 아래 그림은 3개의 프로듀서와 2개의 컨슈머 그룹, 3개의 브로커, 그리고 2개의 토픽이 존재하는 카프카 아키텍처입니다. 내결함성을 유지하기 위해 각 브로커에 복제본Replica을 두어 3개의 Replica가 존재합니다. 토픽 Foo는 컨슈머 그룹 A가, Bar는 컨슈머 그룹 B가 구독합니다. 각 컨슈머 그룹 안에 여러 개의 컨슈머 모듈들이 존재하는 것을 확인할 수 있습니다.
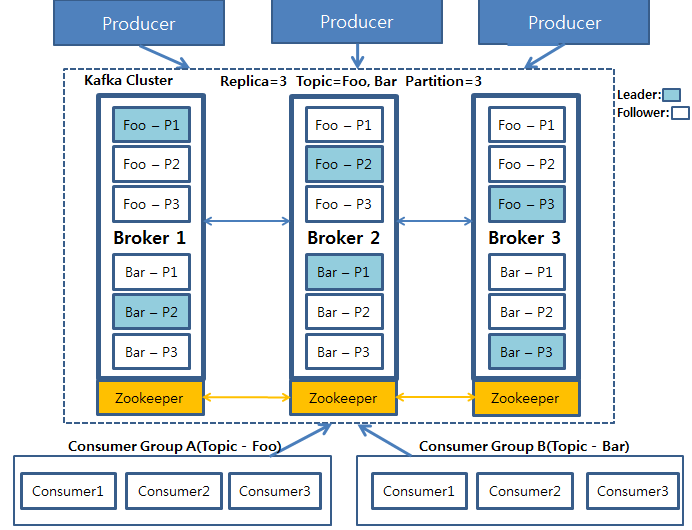
토픽 Foo와 Bar는 3개의 파티션을 갖습니다. 각 파티션은 리더 브로커를 갖고있는데, Foo의 경우 1번 파티션 P1의 리더 브로커는 1번, 2번 파티션 P2의 리더 브로커는 2번, Bar의 경우 1번 파티션 P1의 리더 브로커는 2번.... 같이 이를 확인할 수 있습니다. 카프카 레코드의 읽기와 쓰기 연산은 각 파티션의 리더 브로커에서만 일어납니다. 아래 이미지를 확인합시다.
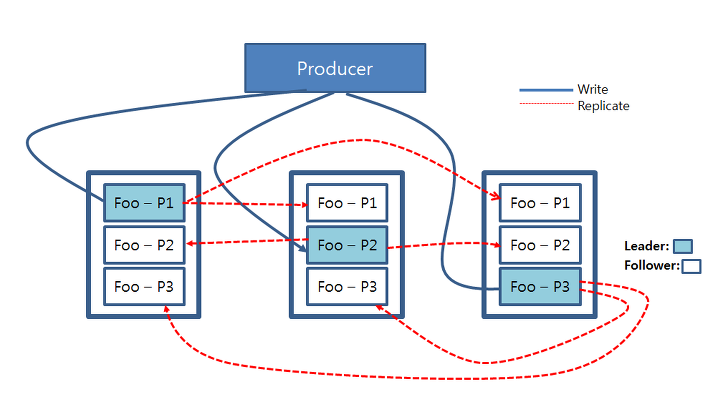
Foo 토픽의 경우 1번 파티션의 RW는 1번 브로커에서만, 2번과 3번 파티션의 경우 2번과 3번 브로커에서만 RW 연산이 일어난다는 것입니다. 이 과정에서 하나의 브로커에 장애가 날 경우 zookeeper는 리더 브로커를 다시 선출해서 지정된 replica 데이터를 사용할 수 있도록 조정합니다.
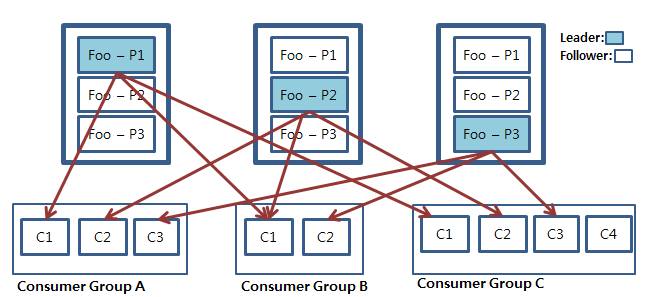
같은 토픽의 파티션은 해당 토픽을 구독하는 컨슈머 그룹의 각 컨슈머들에게 나눠서 전송됩니다. 각 컨슈머들이 각 파티션을 담당한다고 이해하면 좋겠습니다. 때문에 파티션과 토픽의 컨슈머 수가 일치하면 컨슈머가 각 파티션을 전담하고(Group A), 컨슈머의 수가 더 적으면 하나의 컨슈머가 여러 개의 파티션을 담당해야하고(Group B), 컨슈머의 수가 더 많으면 유휴 컨슈머가 생깁니다(Group C).
3. 카프카의 특징
카프카가 분산 메세징 시스템으로서 특별하게 가지고 있는 특징을 다시 정리해보겠습니다.
- Pub/Sub 구조로, 하나의 메세지를 여러 컨슈머 그룹이 동시에 구독할 수 있습니다. RabbitMQ나 ActiveMQ같이 메세지 큐를 목적으로 설계된 솔루션들은 Point to Point 통신을 기본으로 하기 때문에
- 기본적으로 레코드가 디스크에 저장됩니다. 다른 MQ 시스템의 경우 역시 추가 설정을 통해 사용되는 메세지에 영속성을 추가할 수 있지만 카프카는 조금 더 높은 내구성을 가지고 있습니다.
- 대규모 데이터 처리에 특화되었습니다. 비교적 간단한 메세징 시스템 처리보단 전체 시스템을 아울러 사용되는 대용량 데이터 스트림 처리, 로그 수집, 이벤트 기반 아키텍처에 적합한 구조와 성능을 가지고 있습니다.